
MIMIC-II IAC Patient Trajectory and Fate#
In the previous introduction tutorial, we explored the MIMIC-II IAC dataset, comprising electronic health records (EHR) of 1776 patients in 46 features, and identified patient group-specific clusters using ehrapy. Please go through the MIMIC-II IAC introduction before performing this tutorial to get familiar with the dataset.
As a next step, we want to determine patient trajectories and patient fate. The goal is to detect terminal states and the corresponding origins based on pseudotime. Real time very rarely reflects the actual progression of a disease. When measurements are done in a single snapshot or cross-sectional setting, some patients will show no sign of disease (e.g. healthy or recovered), some are at the onset of a specific disease and some are in a more severe stage or even at the height. For an appropriate analysis, we are interested in a continuous transition of states, such as from healthy to diseased to death, for which the real time is therefore not available or informative. Identification of transition states can be achieved by identifying source states (e.g. healthy) and then calculating pseudotime from this state. Based on Markov chain modelling, we uncover patient dynamics using CellRank. For more details, please read CellRank paper 1 and CellRank paper 2.
In this tutorial we will be using CellRank to:
Simulate patient trajectories with random walks.
Compute patient macrostates and infer fate probabilities towards predicted terminal states.
Identify potential driver features for each identified trajectory.
Visualize feature trends along specific patient states, while accounting for the continuous nature of fate determination.
Before performing this tutorial, we highly recommend to read the extensive and well written CellRank documentation, especially the general tutorial chapter is useful. If you are not familiar with single-cell data, do not be afraid and replace cells with patients visits and genes with features in your mind.
This tutorial requires cellrank to be installed. As this packages is not a dependency of ehrapy, it must be installed separately.
%env NUMBA_CPU_NAME=generic
env: NUMBA_CPU_NAME=generic
Before we start with the patient fate analysis of the MIMIC-II IAC dataset, we set up our environment including the import of packages and preparation of the dataset.
Environment setup#
Ensure that the latest version of ehrapy is installed. A list of all dependency versions can be found at the end of this tutorial.
import anndata as ad
import cellrank as cr
import ehrapy as ep
import ehrdata as ed
import numpy as np
We are ignoring a few warnings for readability reasons.
import warnings
warnings.filterwarnings("ignore")
We set a flag for numba to improve reproducibility across different machines:
Getting and preprocessing the MIMIC-II dataset#
This tutorial is based on the MIMIC-II IAC dataset which was previously introduced in the MIMIC-II IAC introduction tutorial.
edata = ed.dt.mimic_2()
edata
EHRData object with n_obs × n_vars × n_t = 1776 × 46 × 1
shape of .X: (1776, 46)
The MIMIC-II dataset has 1776 patients with 46 features.
Now that we have our EHRData object ready, we need to perform the standard preprocessing steps as performed in the introduction tutorial again before we can use ehrapy and CellRank for patient fate analysis.
ed.infer_feature_types(edata, binary_as="numeric")
! Feature was detected as categorical features stored numerically. Adjust using `ed.replace_feature_types` if needed.
Detected feature types for EHRData object with 1776 obs and 46 vars ╠══ 📅 Date features ╠══ 📐 Numerical features ║ ╠══ abg_count ║ ╠══ afib_flg ║ ╠══ age ║ ╠══ aline_flg ║ ╠══ bmi ║ ╠══ bun_first ║ ╠══ cad_flg ║ ╠══ censor_flg ║ ╠══ chf_flg ║ ╠══ chloride_first ║ ╠══ copd_flg ║ ╠══ creatinine_first ║ ╠══ day_28_flg ║ ╠══ day_icu_intime_num ║ ╠══ gender_num ║ ╠══ hgb_first ║ ╠══ hosp_exp_flg ║ ╠══ hospital_los_day ║ ╠══ hour_icu_intime ║ ╠══ hr_1st ║ ╠══ icu_exp_flg ║ ╠══ icu_los_day ║ ╠══ iv_day_1 ║ ╠══ liver_flg ║ ╠══ mal_flg ║ ╠══ map_1st ║ ╠══ mort_day_censored ║ ╠══ pco2_first ║ ╠══ platelet_first ║ ╠══ po2_first ║ ╠══ potassium_first ║ ╠══ renal_flg ║ ╠══ resp_flg ║ ╠══ sapsi_first ║ ╠══ sepsis_flg ║ ╠══ service_num ║ ╠══ sodium_first ║ ╠══ sofa_first ║ ╠══ spo2_1st ║ ╠══ stroke_flg ║ ╠══ tco2_first ║ ╠══ temp_1st ║ ╠══ wbc_first ║ ╚══ weight_first ╚══ 🗂️ Categorical features ╠══ day_icu_intime (7 categories) ╚══ service_unit (3 categories)
%%capture
edata = ep.pp.encode(edata, autodetect=True)
ep.pp.knn_impute(edata, n_neighbors=5, backend="scikit-learn", var_names = edata.var_names[edata.var["feature_type"] == "numeric"])
ep.pp.log_norm(edata, vars=["iv_day_1", "po2_first"], offset=1)
ep.pp.pca(edata, svd_solver="randomized", random_state=42)
ep.pp.neighbors(edata, transformer="sklearn", n_pcs=10)
ep.tl.umap(edata)
ep.tl.leiden(edata, resolution=0.3, key_added="leiden_0_3")
ep.settings.set_figure_params(figsize=(5, 4), dpi=100)
ep.pl.umap(edata, color=["leiden_0_3"], title="Leiden 0.3", size=20)
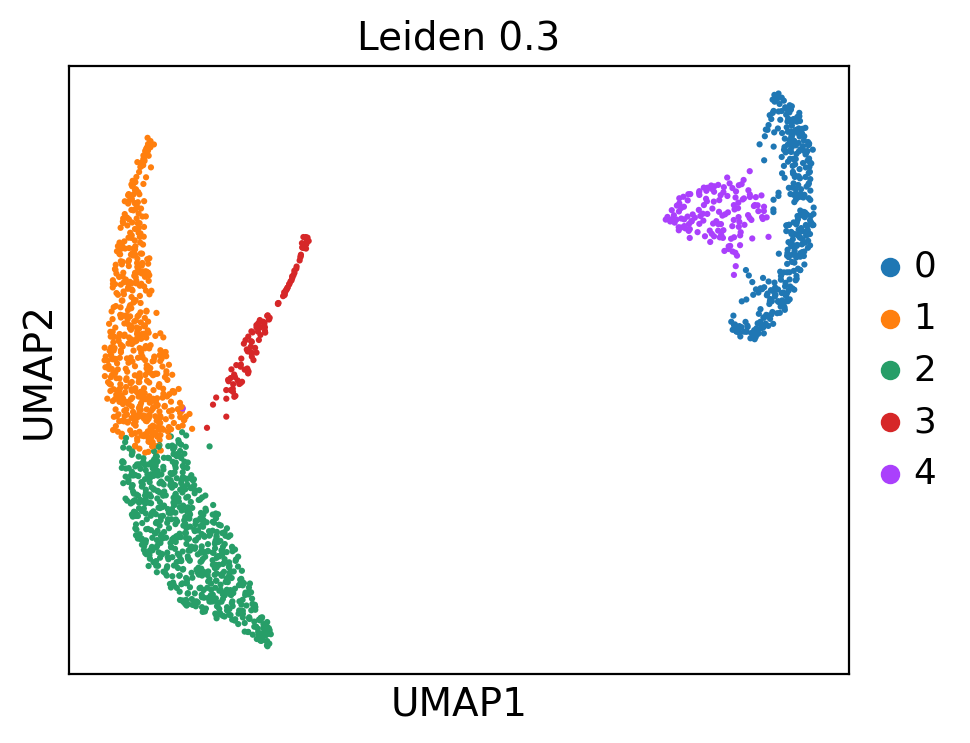
This UMAP embedding is exactly the same as previously computed in the MIMIC-II IAC introduction tutorial. Now we continue with the patient fate analysis.
Analysis using ehrapy and CellRank#
Depending on the data it may not always be possible to clearly define a cluster or specific patient visits as the origin or terminus of a trajectory. Working with single-cell data simplifies matters since the detection of stem cells generally signifies the start of cell differentiation.
In this tutorial, we will define a patient cluster as the origin (root cluster) and explore possible terminal states.
Pseudotime calculation#
As the root cluster for pseudotime calculation we choose cluster 0 since patients in that cluster do not show very severe comorbidities and features yet. Then we calculate the Diffusion Pseudotime.
edata = ad.AnnData(edata)
edata.uns["iroot"] = np.flatnonzero(edata.obs["leiden_0_3"] == "0")[0]
ep.tl.dpt(edata)
WARNING: Trying to run `tl.dpt` without prior call of `tl.diffmap`. Falling back to `tl.diffmap` with default parameters.
Now we define the kernel, compute the transition matrix and plot a projection onto the UMAP.
Determining patient fate with a PseudotimeKernel#
The PseudotimeKernel computes direct transition probabilities based on a KNN graph and pseudotime.
The KNN graph contains information about the (undirected) conductivities among patients, reflecting their similarity. Pseudotime can be used to either remove edges that point against the direction of increasing pseudotime, or to downweight them.
from cellrank.kernels import PseudotimeKernel
pk = PseudotimeKernel(edata, time_key="dpt_pseudotime")
pk.compute_transition_matrix()
INFO Computing transition matrix based on pseudotime
INFO Finish (0.51s)
PseudotimeKernel[n=1776, dnorm=False, scheme='hard', frac_to_keep=0.3]
ep.settings.set_figure_params(figsize=(5, 4), dpi=100)
pk.plot_projection(basis="umap", color="leiden_0_3")
INFO Projecting transition matrix onto 'umap'
INFO Adding `adata.obsm['T_fwd_umap']` (0.33s)
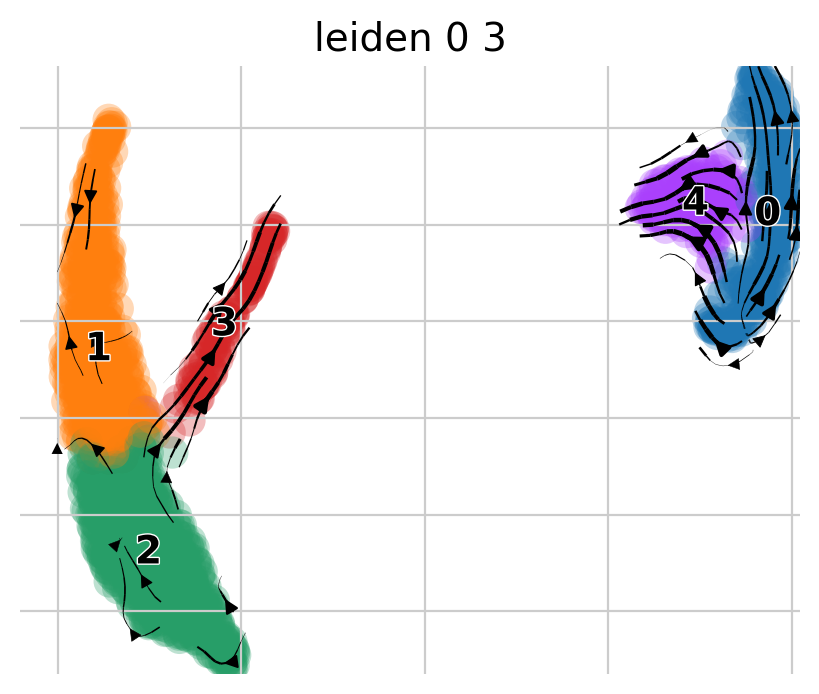
We observe two main trajectories originating from cluster 0 going to clusters 2, 3, and 5. Let’s check the metedata again.
ep.pl.umap(edata, color="censor_flg", title="Censored or Death (0 = death, 1 = censored)")
ep.pl.umap(
edata,
color="mort_day_censored",
title="Day post ICU admission of censoring or death",
)
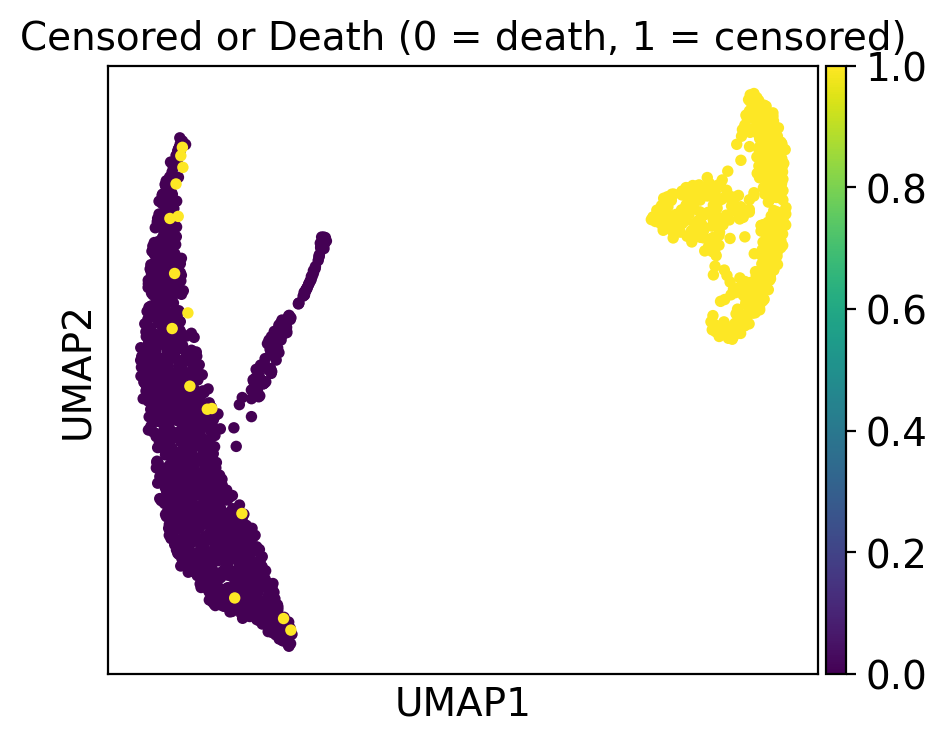
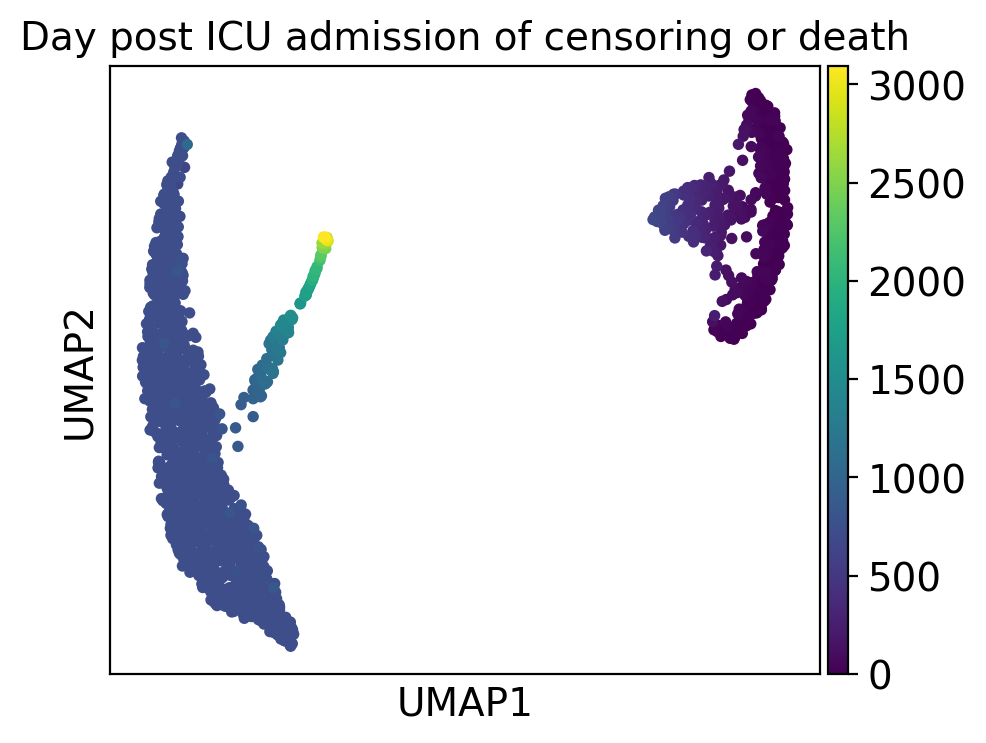
Cluster 4 and 1 consist of patients that deceased, while cluster 5 includes patients with a high day post ICU admission.
Simulating transitions with random walks#
Cellrank makes it easy to simulate the behavior of random walks from specific clusters. This allows us to not only visualize where the patients end up, but also roughly how many in which clusters after a defined number of iterations. We can either just start walking…
pk.plot_random_walks(
seed=0,
n_sims=100,
start_ixs={"leiden_0_3": ["0"]},
legend_loc="right",
dpi=100,
show_progress_bar=False,
)
INFO Simulating 100 random walks of maximum length 444
INFO Finish (3.40s)
INFO Plotting random walks
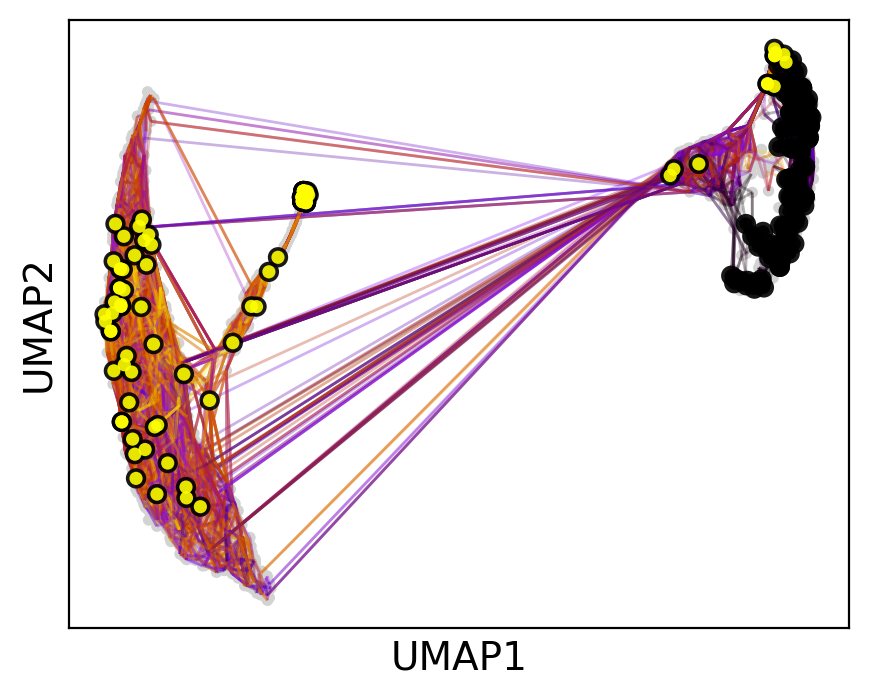
… or set a number of required hits in one or more terminal clusters. Here, we require 50 hits in cluster 2 or 5.
pk.plot_random_walks(
seed=0,
n_sims=100,
start_ixs={"leiden_0_3": ["0"]},
stop_ixs={"leiden_0_3": ["2", "5"]},
successive_hits=50,
legend_loc="right",
dpi=100,
show_progress_bar=False,
)
INFO Simulating 100 random walks of maximum length 444
INFO Finish (3.21s)
INFO Plotting random walks
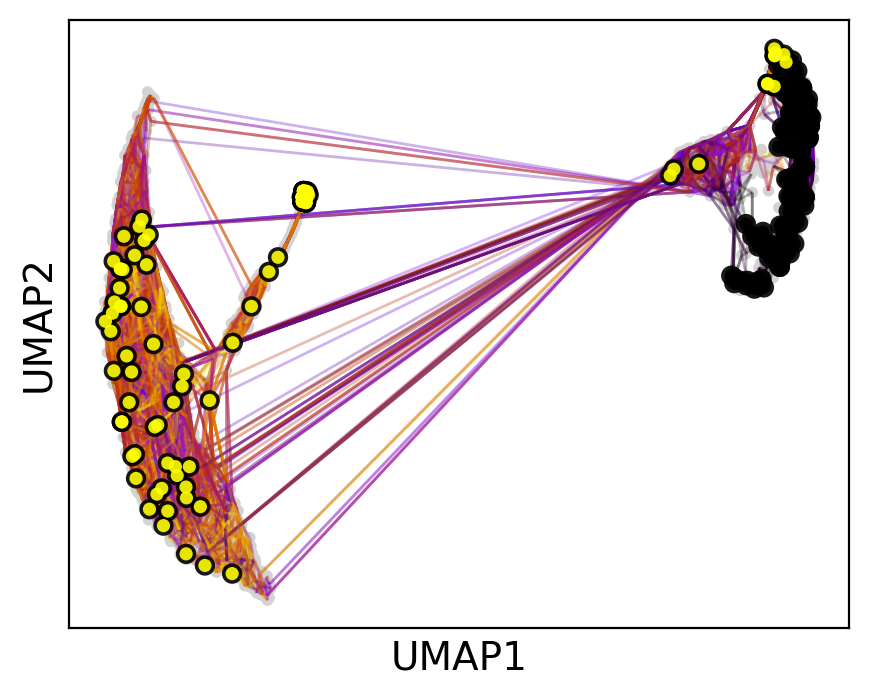
Black and yellow dots indicate random walk start and terminal patient visits, respectively.
Determining macrostates and terminal states#
To find the terminal states of cluster 0, well will use an estimator to predict the patient fates using the above calculated transition matrix. The main objective is to decompose the patient state space into a set of macrostates, that represent the slow-time scale dynamics of the process and predict terminal states. Here, we will use an Generalized Perron Cluster Cluster Analysis (GPCCA) estimator.
As a first step we try to identify macrostates in the data using the fit() function.
# Check if pseudotime was computed
print("Pseudotime key exists:", "dpt_pseudotime" in edata.obs)
if "dpt_pseudotime" in edata.obs:
print("Pseudotime range:", edata.obs["dpt_pseudotime"].min(), "to", edata.obs["dpt_pseudotime"].max())
print("Any NaN values:", edata.obs["dpt_pseudotime"].isna().sum())
Pseudotime key exists: True
Pseudotime range: 0.0 to 1.0
Any NaN values: 0
g = cr.estimators.GPCCA(pk)
g.fit(cluster_key="leiden_0_3")
g.macrostates_memberships
INFO Computing eigendecomposition of the transition matrix
INFO Adding `adata.uns['eigendecomposition_fwd']`
`.eigendecomposition`
Finish (0.16s)
WARNING Unable to import `petsc4py` or `slepc4py`. Using `method='brandts'`
WARNING For `method='brandts'`, dense matrix is required. Densifying
INFO Computing Schur decomposition
INFO Adding `adata.uns['eigendecomposition_fwd']`
`.schur_vectors`
`.schur_matrix`
`.eigendecomposition`
Finish (3.40s)
INFO Computing 3 macrostates
INFO Adding `.macrostates`
`.macrostates_memberships`
`.coarse_T`
`.coarse_initial_distribution
`.coarse_stationary_distribution`
`.schur_vectors`
`.schur_matrix`
`.eigendecomposition`
Finish (2.54s)
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
File /ictstr01/home/icb/eljas.roellin/miniforge3/envs/ehrdata_ehrapy_env_mar/lib/python3.12/site-packages/IPython/core/formatters.py:770, in PlainTextFormatter.__call__(self, obj)
763 stream = StringIO()
764 printer = pretty.RepresentationPrinter(stream, self.verbose,
765 self.max_width, self.newline,
766 max_seq_length=self.max_seq_length,
767 singleton_pprinters=self.singleton_printers,
768 type_pprinters=self.type_printers,
769 deferred_pprinters=self.deferred_printers)
--> 770 printer.pretty(obj)
771 printer.flush()
772 return stream.getvalue()
File /ictstr01/home/icb/eljas.roellin/miniforge3/envs/ehrdata_ehrapy_env_mar/lib/python3.12/site-packages/IPython/lib/pretty.py:420, in RepresentationPrinter.pretty(self, obj)
409 return meth(obj, self, cycle)
410 if (
411 cls is not object
412 # check if cls defines __repr__
(...) 418 and callable(_safe_getattr(cls, "__repr__", None))
419 ):
--> 420 return _repr_pprint(obj, self, cycle)
422 return _default_pprint(obj, self, cycle)
423 finally:
File /ictstr01/home/icb/eljas.roellin/miniforge3/envs/ehrdata_ehrapy_env_mar/lib/python3.12/site-packages/IPython/lib/pretty.py:795, in _repr_pprint(obj, p, cycle)
793 """A pprint that just redirects to the normal repr function."""
794 # Find newlines and replace them with p.break_()
--> 795 output = repr(obj)
796 lines = output.splitlines()
797 with p.group():
File /ictstr01/home/icb/eljas.roellin/miniforge3/envs/ehrdata_ehrapy_env_mar/lib/python3.12/site-packages/cellrank/_utils/_lineage.py:887, in Lineage.__repr__(self)
886 def __repr__(self) -> str:
--> 887 return f"{super().__repr__()[:-1]},\n names([{', '.join(self.names)}]))"
File /ictstr01/home/icb/eljas.roellin/miniforge3/envs/ehrdata_ehrapy_env_mar/lib/python3.12/site-packages/numpy/_core/arrayprint.py:1614, in _array_repr_implementation(arr, max_line_width, precision, suppress_small, array2string)
1612 lst = repr(arr.item())
1613 else:
-> 1614 lst = array2string(arr, max_line_width, precision, suppress_small,
1615 ', ', prefix, suffix=")")
1617 # Add dtype and shape information if these cannot be inferred from
1618 # the array string.
1619 extras = []
File /ictstr01/home/icb/eljas.roellin/miniforge3/envs/ehrdata_ehrapy_env_mar/lib/python3.12/site-packages/numpy/_core/arrayprint.py:802, in array2string(a, max_line_width, precision, suppress_small, separator, prefix, formatter, threshold, edgeitems, sign, floatmode, suffix, legacy)
799 if a.size == 0:
800 return "[]"
--> 802 return _array2string(a, options, separator, prefix)
File /ictstr01/home/icb/eljas.roellin/miniforge3/envs/ehrdata_ehrapy_env_mar/lib/python3.12/site-packages/numpy/_core/arrayprint.py:587, in _recursive_guard.<locals>.decorating_function.<locals>.wrapper(self, *args, **kwargs)
585 repr_running.add(key)
586 try:
--> 587 return f(self, *args, **kwargs)
588 finally:
589 repr_running.discard(key)
File /ictstr01/home/icb/eljas.roellin/miniforge3/envs/ehrdata_ehrapy_env_mar/lib/python3.12/site-packages/numpy/_core/arrayprint.py:620, in _array2string(a, options, separator, prefix)
617 # skip over array(
618 next_line_prefix += " " * len(prefix)
--> 620 lst = _formatArray(a, format_function, options['linewidth'],
621 next_line_prefix, separator, options['edgeitems'],
622 summary_insert, options['legacy'])
623 return lst
File /ictstr01/home/icb/eljas.roellin/miniforge3/envs/ehrdata_ehrapy_env_mar/lib/python3.12/site-packages/numpy/_core/arrayprint.py:961, in _formatArray(a, format_function, line_width, next_line_prefix, separator, edge_items, summary_insert, legacy)
957 return s
959 try:
960 # invoke the recursive part with an initial index and prefix
--> 961 return recurser(index=(),
962 hanging_indent=next_line_prefix,
963 curr_width=line_width)
964 finally:
965 # recursive closures have a cyclic reference to themselves, which
966 # requires gc to collect (gh-10620). To avoid this problem, for
967 # performance and PyPy friendliness, we break the cycle:
968 recurser = None
File /ictstr01/home/icb/eljas.roellin/miniforge3/envs/ehrdata_ehrapy_env_mar/lib/python3.12/site-packages/numpy/_core/arrayprint.py:934, in _formatArray.<locals>.recurser(index, hanging_indent, curr_width)
931 line_sep = separator.rstrip() + '\n' * (axes_left - 1)
933 for i in range(leading_items):
--> 934 nested = recurser(
935 index + (i,), next_hanging_indent, next_width
936 )
937 s += hanging_indent + nested + line_sep
939 if show_summary:
File /ictstr01/home/icb/eljas.roellin/miniforge3/envs/ehrdata_ehrapy_env_mar/lib/python3.12/site-packages/numpy/_core/arrayprint.py:914, in _formatArray.<locals>.recurser(index, hanging_indent, curr_width)
911 line += separator
913 for i in range(trailing_items, 1, -1):
--> 914 word = recurser(index + (-i,), next_hanging_indent, next_width)
915 s, line = _extendLine_pretty(
916 s, line, word, elem_width, hanging_indent, legacy)
917 line += separator
File /ictstr01/home/icb/eljas.roellin/miniforge3/envs/ehrdata_ehrapy_env_mar/lib/python3.12/site-packages/numpy/_core/arrayprint.py:865, in _formatArray.<locals>.recurser(index, hanging_indent, curr_width)
862 axes_left = a.ndim - axis
864 if axes_left == 0:
--> 865 return format_function(a[index])
867 # when recursing, add a space to align with the [ added, and reduce the
868 # length of the line by 1
869 next_hanging_indent = hanging_indent + ' '
File /ictstr01/home/icb/eljas.roellin/miniforge3/envs/ehrdata_ehrapy_env_mar/lib/python3.12/site-packages/numpy/_core/arrayprint.py:1111, in FloatingFormat.__call__(self, x)
1106 return ' ' * (
1107 self.pad_left + self.pad_right + 1 - len(ret)
1108 ) + ret
1110 if self.exp_format:
-> 1111 return dragon4_scientific(x,
1112 precision=self.precision,
1113 min_digits=self.min_digits,
1114 unique=self.unique,
1115 trim=self.trim,
1116 sign=self.sign == '+',
1117 pad_left=self.pad_left,
1118 exp_digits=self.exp_size)
1119 else:
1120 return dragon4_positional(x,
1121 precision=self.precision,
1122 min_digits=self.min_digits,
(...) 1127 pad_left=self.pad_left,
1128 pad_right=self.pad_right)
TypeError: only 0-dimensional arrays can be converted to Python scalars
| 3 | 0 | 1 |
|---|---|---|
| 0.010474 | 0.615957 | 0.373568 |
| 0.102105 | 0.000010 | 0.897885 |
| 0.024003 | 0.000002 | 0.975995 |
| 0.000215 | 0.998952 | 0.000833 |
| 0.131360 | 0.000013 | 0.868627 |
| 0.051830 | 0.000005 | 0.948165 |
| 0.090919 | 0.000009 | 0.909072 |
| 0.133847 | 0.000013 | 0.866139 |
| 0.111635 | 0.000011 | 0.888354 |
| 0.001217 | 0.938613 | 0.060170 |
| ... | ... | ... |
| 0.052499 | 0.030626 | 0.916875 |
| 0.000782 | 0.949494 | 0.049725 |
| 0.509039 | 0.000050 | 0.490911 |
| 0.264568 | 0.000026 | 0.735406 |
| 0.001815 | 0.952106 | 0.046078 |
| 0.056890 | 0.000006 | 0.943104 |
| 0.000566 | 0.992218 | 0.007216 |
| 0.007773 | 0.695925 | 0.296301 |
| 0.003807 | 0.881055 | 0.115138 |
| 0.060716 | 0.006105 | 0.933180 |
1776 cells x 3 lineages
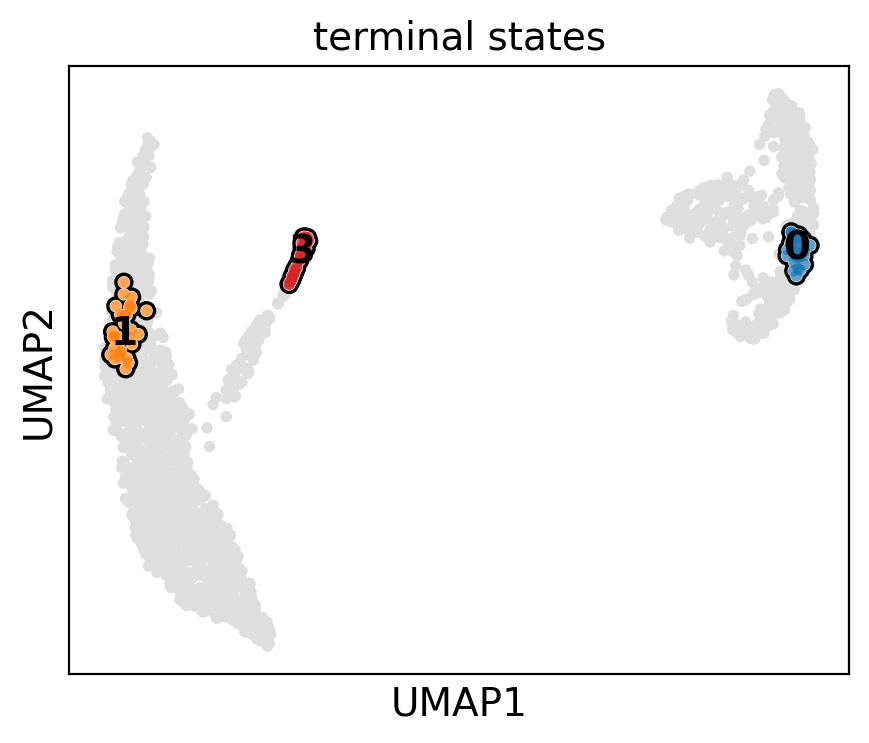
g.predict_terminal_states()
g.plot_macrostates(which="terminal")
INFO Adding `adata.obs['term_states_fwd']`
`adata.obs['term_states_fwd_probs']`
`.terminal_states`
`.terminal_states_probabilities`
`.terminal_states_memberships
Finish`
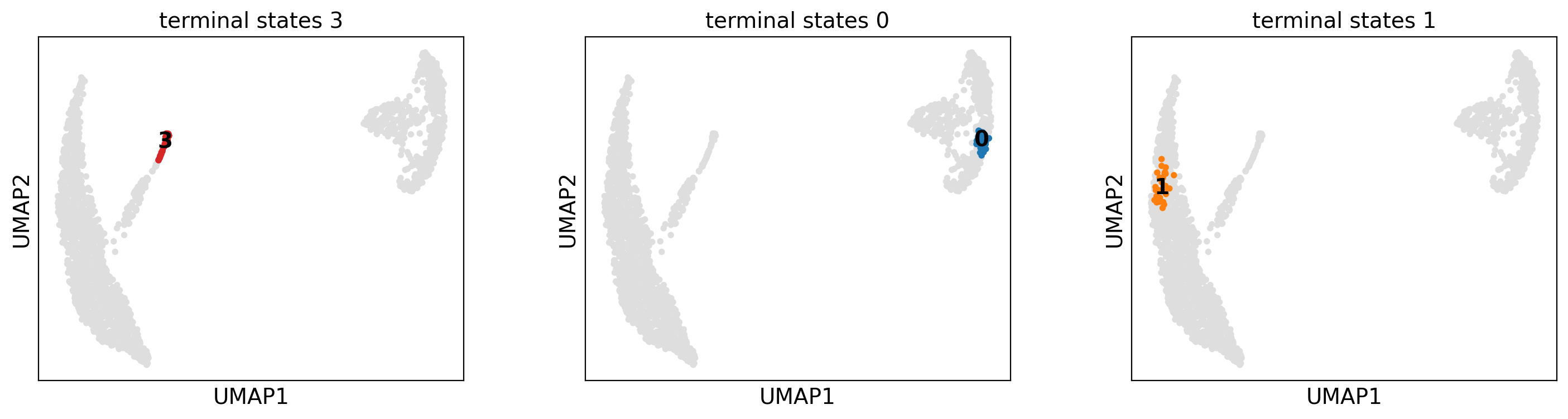
g.plot_macrostates(which="terminal", same_plot=False)
As a next step we will calculate the fate probabilities. For each patient visit, this computes the probability of being absorbed in any of the terminal states by aggregating over all random walks that start in a given patient visit and end in some terminal population.
g.compute_fate_probabilities(preconditioner="ilu", tol=1e-15)
g.plot_fate_probabilities()
INFO Computing fate probabilities
WARNING `1` solution(s) did not converge
INFO Adding `adata.obsm['lineages_fwd']`
`.fate_probabilities`
Finish (60.64s)

The plot above combines fate probabilities towards all terminal states, each patient visit is colored according to its most likely fate, color intensity reflects the degree of fate priming.
g.plot_fate_probabilities(same_plot=False)
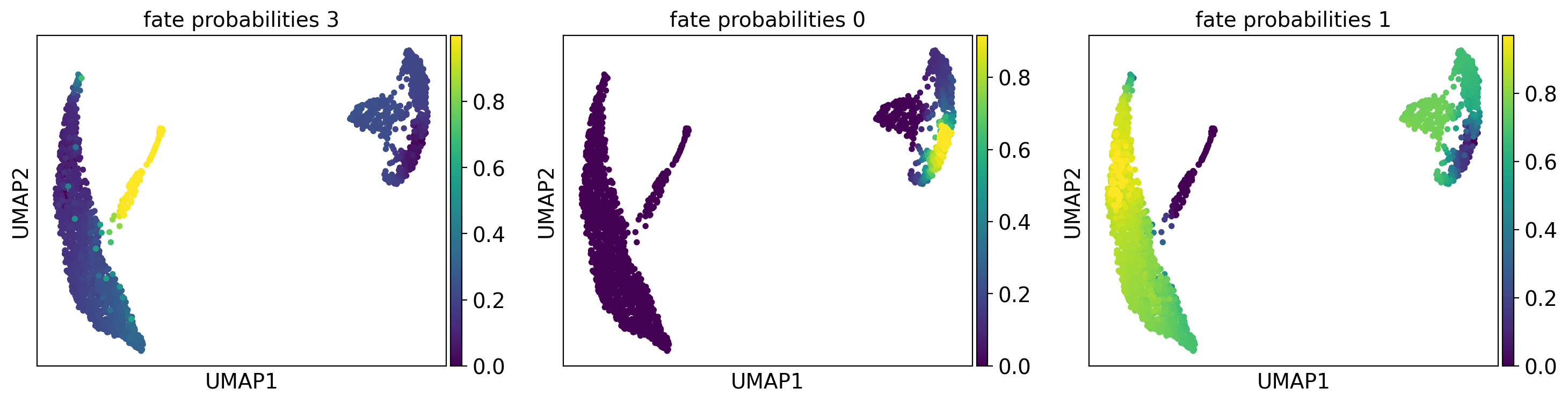
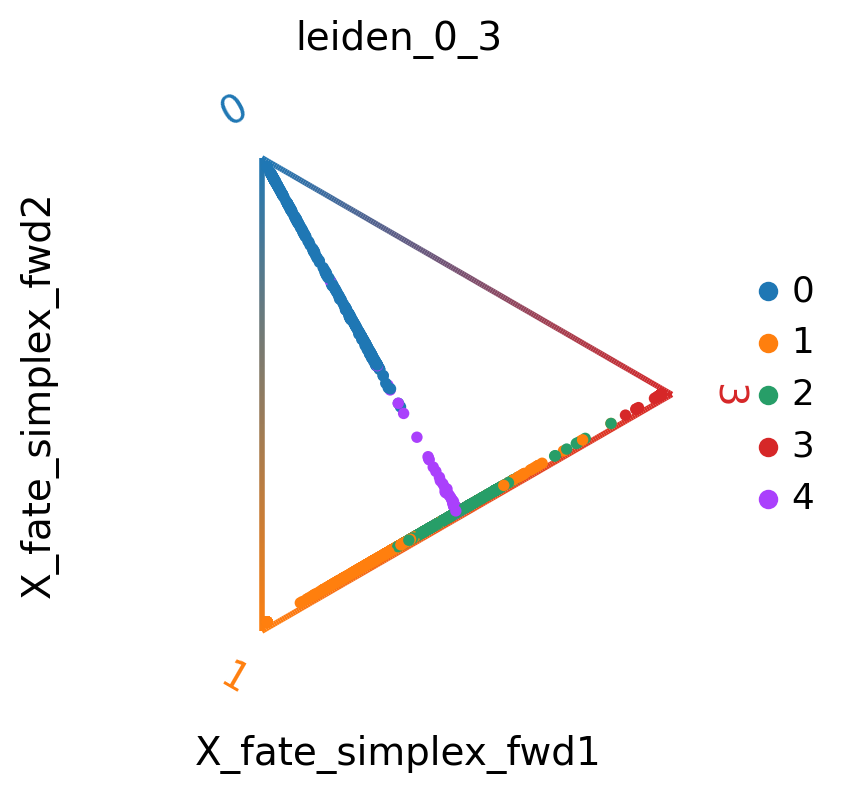
We can also visualize the fate probabilities jointly in a circular projection where each dot represents a patient visit, colored by cluster labels. Patient visits are arranged inside the circle according to their fate probabilities, fate biased visits are placed next to their corresponding corner while undetermined patient fates are placed in the middle.
edata.obsm.keys()
KeysView(AxisArrays with keys: X_pca, X_umap, X_diffmap, T_fwd_umap, schur_vectors_fwd, macrostates_fwd_memberships, term_states_fwd_memberships, lineages_fwd)
cr.pl.circular_projection(edata, keys="leiden_0_3", legend_loc="right")
Identification of driver features#
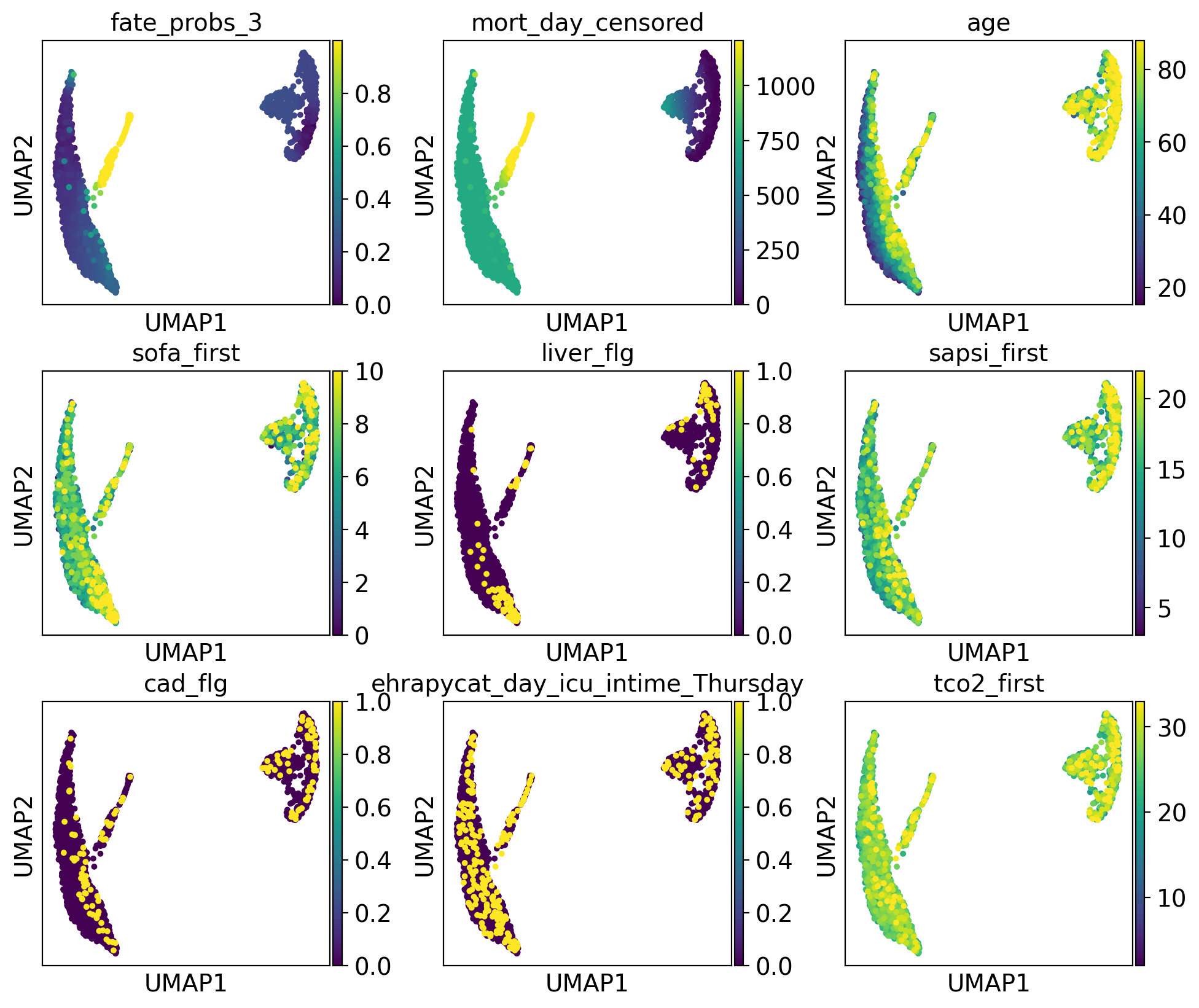
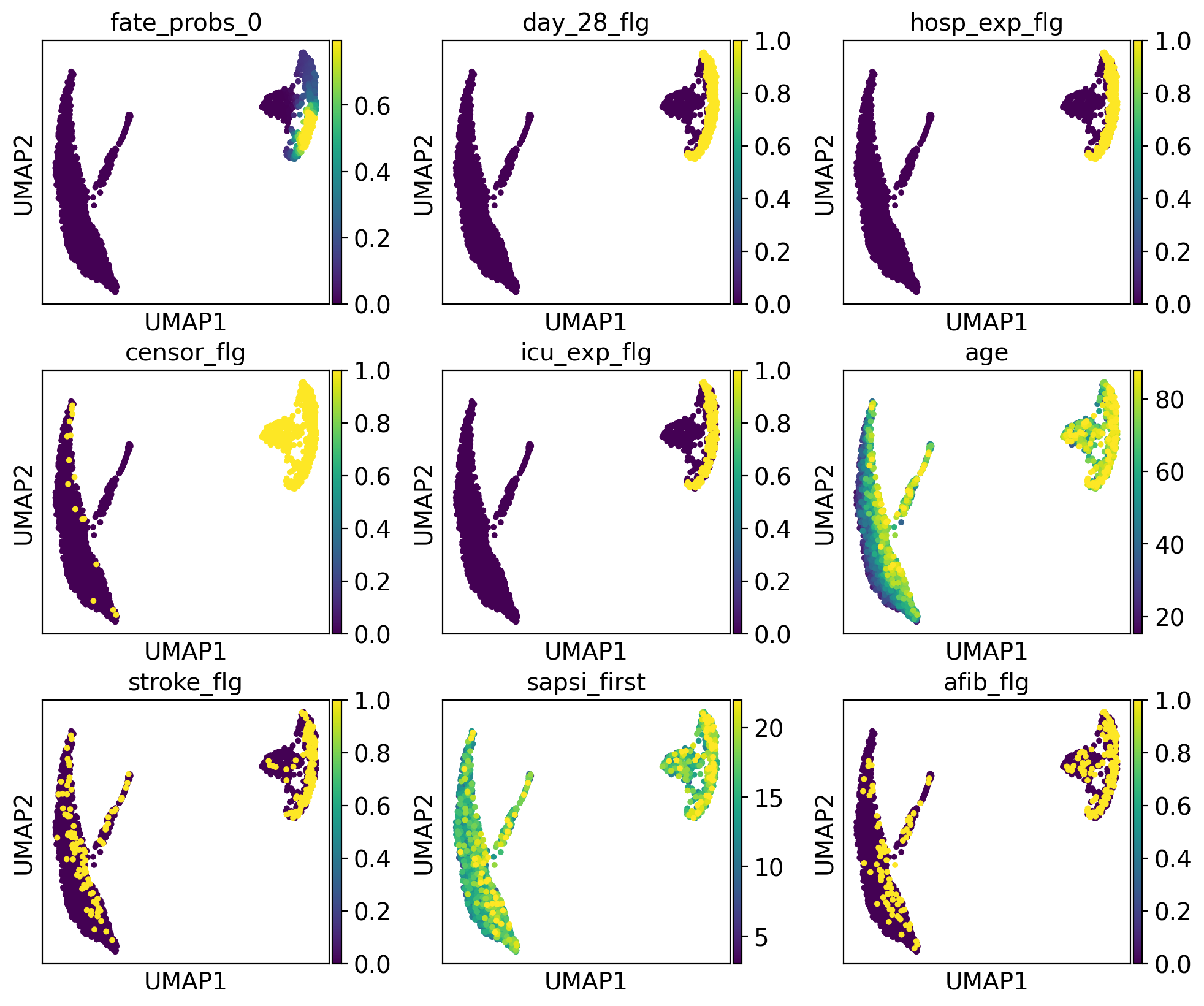
We uncover putative driver features by correlating fate probabilities with features using the compute_lineage_drivers() method. In other words, if a feature is systematically higher or lower in patient visits that are more or less likely to differentiate towards a given terminal state, respectively, then we call this feature a putative driver feature.
We calculate these driver features for our lineages:
%%capture
ep.settings.set_figure_params(figsize=(3, 3), dpi=100)
for lineage in g.macrostates_memberships._names:
drivers = g.compute_lineage_drivers(lineages=lineage)
edata.obs[f"fate_probs_{lineage}"] = g.fate_probabilities[lineage].X.flatten()
ep.pl.umap(
edata,
color=[f"fate_probs_{lineage}"] + list(drivers.index[:8]),
color_map="viridis",
s=50,
ncols=3,
vmax="p96",
)
INFO Adding `adata.varm['terminal_lineage_drivers']`
`.lineage_drivers`
Finish (2.40s)
INFO Adding `adata.varm['terminal_lineage_drivers']`
`.lineage_drivers`
Finish (0.00s)
INFO Adding `adata.varm['terminal_lineage_drivers']`
`.lineage_drivers`
Finish (0.00s)
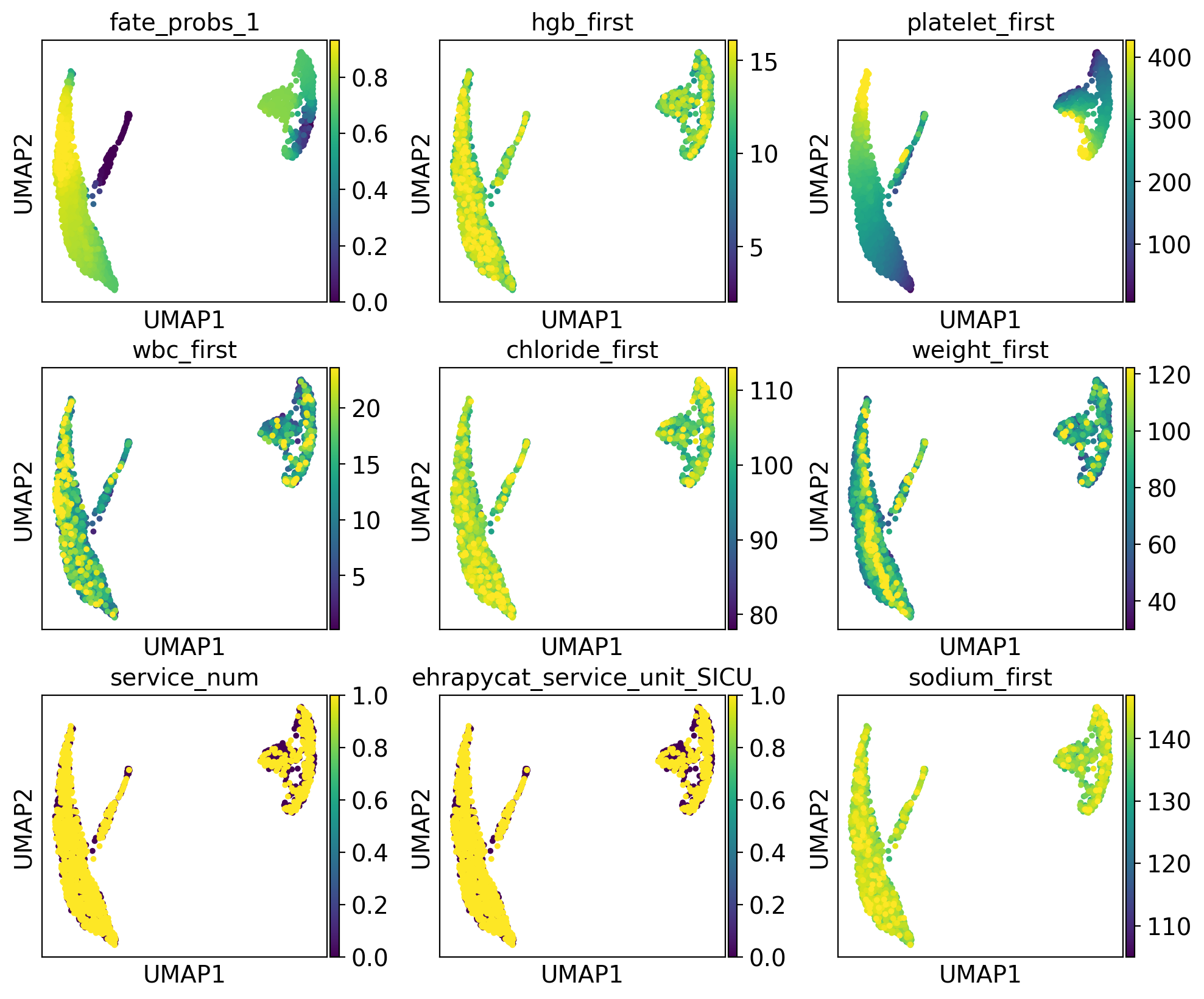
The lineage 1_1 seems to have a lot of patients that deceased in hospital, are of high age and had a high platelet measurement, while lineage 1_2 consists of patients that deceased in hospital, had a high first SAPS I and SOFA score and lineage 5 consists of patients with a high number of days after ICU release.
Determining feature trends#
Given fate probabilities and a pseudotime, we can plot trajectory-specific feature trends. Specifically, we fit Generalized Additive Models (GAMs), weighting each observation’s (here patients) contribution to each trajectory according to its vector of fate probabilities. We start by initializing a model.
model = cr.models.GAM(edata)
With the model initialized, we can visualize feature dynamics along specific trajectories. Here, we have a closer look at a selection of features that were previously identified as lineage drivers.
cr.pl.gene_trends(
edata,
model,
[
"sapsi_first",
"sofa_first",
"age",
"weight_first",
"sodium_first",
"chloride_first",
"platelet_first",
"wbc_first",
],
time_key="dpt_pseudotime",
show_progress_bar=False,
same_plot=True,
ncols=2,
hide_cells=True,
figsize=(10, 12),
)
INFO Computing trends using 1 core(s)
INFO Finish (0.30s)
INFO Plotting trends
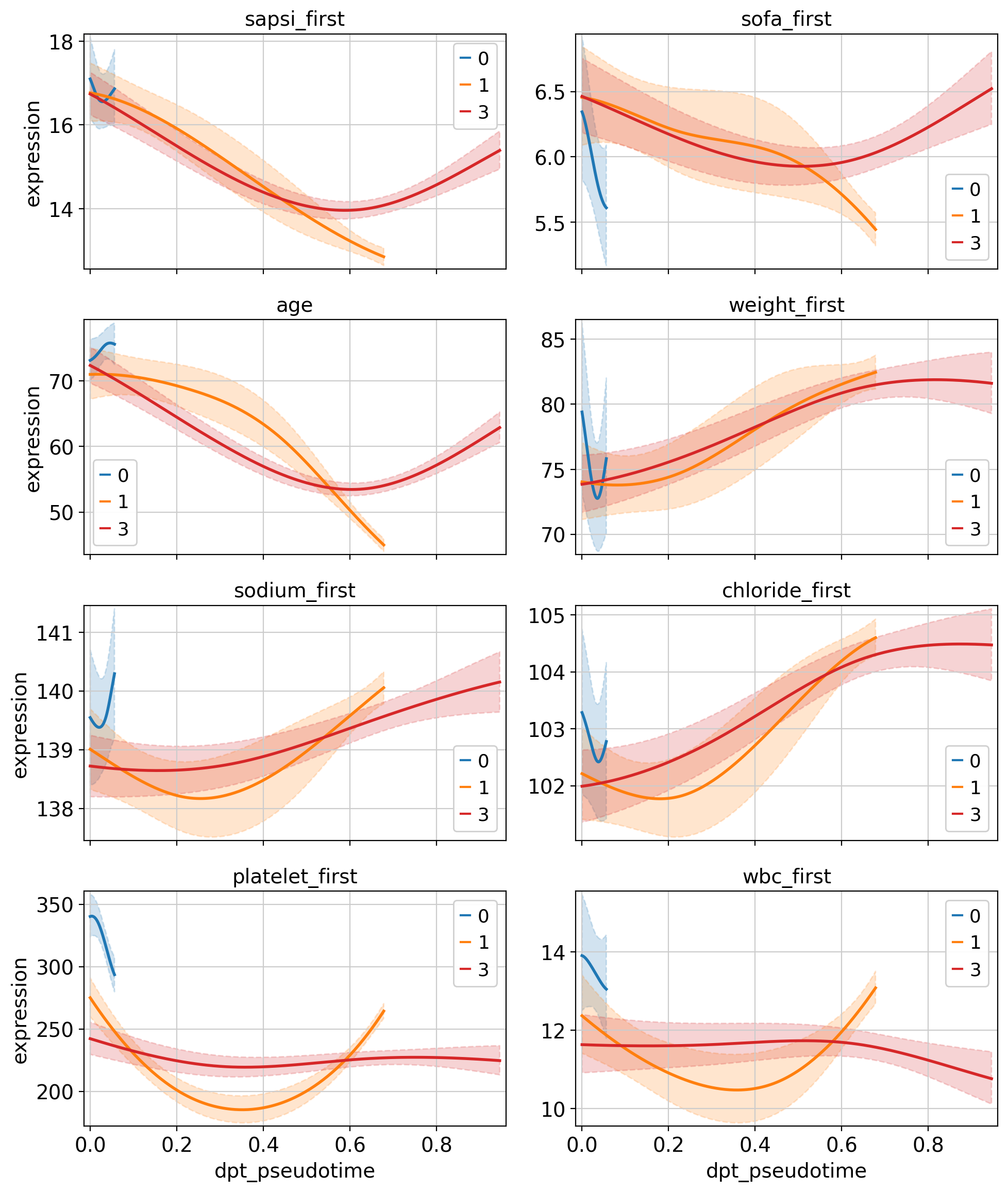
Conclusion#
In this tutorial we applied CellRank and ehrapy to identify patient visit trajectories from selected root clusters, computed macrostates of clusters and pointed out features that are driving those trajectories. Following that, we visualized feature trends across the pseudotime for the patient trajectories. In particular, we inspected trajectories of patients originating from cluster 0, which was defined by less severe features, and identified 3 major trajectories. Two trajectories (2_1 and 2_2) were terminated in a bad outcome cluster and were driven by severity features such as age, death and comorbidities.
As a next tutorial, we suggest to have a closer look at our survival analysis, continue with that tutorials or go back to our tutorial overview page.
References#
Raffa, J. (2016). Clinical data from the MIMIC-II database for a case study on indwelling arterial catheters (version 1.0). PhysioNet. https://doi.org/10.13026/C2NC7F.
Raffa J.D., Ghassemi M., Naumann T., Feng M., Hsu D. (2016) Data Analysis. In: Secondary Analysis of Electronic Health Records. Springer, Cham
Goldberger, A., Amaral, L., Glass, L., Hausdorff, J., Ivanov, P. C., Mark, R., … & Stanley, H. E. (2000). PhysioBank, PhysioToolkit, and PhysioNet: Components of a new research resource for complex physiologic signals. Circulation [Online]. 101 (23), pp. e215–e220.
Marius Lange, Volker Bergen, Michal Klein, Manu Setty, Bernhard Reuter, Mostafa Bakhti, Heiko Lickert, Meshal Ansari, Janine Schniering, Herbert B. Schiller, Dana Pe’er, and Fabian J. Theis. Cellrank for directed single-cell fate mapping. Nat. Methods, 2022. doi:10.1038/s41592-021-01346-6.
Lars Velten, Simon F. Haas, Simon Raffel, Sandra Blaszkiewicz, Saiful Islam, Bianca P. Hennig, Christoph Hirche, Christoph Lutz, Eike C. Buss, Daniel Nowak, Tobias Boch, Wolf-Karsten Hofmann, Anthony D. Ho, Wolfgang Huber, Andreas Trumpp, Marieke A. G. Essers, and Lars M. Steinmetz. Human haematopoietic stem cell lineage commitment is a continuous process. Nature Cell Biology, 19(4):271–281, 2017. doi:10.1038/ncb3493.
Bergen, V., Lange, M., Peidli, S. et al. Generalizing RNA velocity to transient cell states through dynamical modeling. Nat Biotechnol 38, 1408–1414 (2020). https://doi.org/10.1038/s41587-020-0591-3
Haghverdi, L., Büttner, M., Wolf, F. et al. Diffusion pseudotime robustly reconstructs lineage branching. Nat Methods 13, 845–848 (2016). https://doi.org/10.1038/nmeth.3971
Package versions#
!pip list