Note
This page was generated from ml_usecases.ipynb. Some tutorial content may look better in light mode.
Using ehrapy with machine learning#
The notebook is adpated from https://github.com/cmsalgado/book_chapter/blob/master/book_chapter.ipynb
The data used in this notebook was constructed based on the code provided in https://github.com/theislab/ehrapy-datasets/blob/main/mimic3/mimic3_data_preparation.ipynb
Objectives and approach#
This tutorial aims to demonstrate how to use ehrapy with machine learning (ML) to predict clinical outcome.
We will cover a large number of well-known ML algorithms, starting with the simplest (logistic regression and k-nearest neighbours) and ending with more complex ones (random forest), without delving in much detail into the underlying mathematical theory. Instead, we will focus on explaining the intuitions behind algorithms so that you understand how they learn and how you can use and interpret them in any new problem.
A real-world clinical dataset will be used. The data were extracted from the MIMIC-III Clinical Database, which is a large, publicly-available database comprising de-identified electronic health records of approximately 60 000 ICU admissions. Patients stayed in the intensive care unit (ICU) of the Beth Israel Deaconess Medical Center between 2001 and 2012. The MIMIC-III database is described in:
Johnson AEW, Pollard TJ, Shen L, Lehman L, Feng M, Ghassemi M, Moody B, Szolovits P, Celi LA, Mark RG. MIMIC-III, a freely accessible critical care database. Scientific Data (2016).
Before dwelling into ML, this chapter presents the data preparation phase, which consists of a series of steps required to transform raw data from electronic health records into structured data that can be used as input to the learning algorithms. This is a crucial part of any ML project. First, it is crucial to understand what the algorithm is supposed to learn so that you can select appropriate information/variables to describe the problem. In other words, you want to avoid what is frequently referred to as “garbage in garbage out”. Second, since the data is usually not handed in a format that is ready for straightway ML, chances are you will need to spend some time preprocessing and analyzing it before applying ML. You will see that in the end, your results are highly dependent on decisions made during this part. Is does not matter to keep trying to optimize the ML algorithm if you have poor data, your algorithm will not be able to learn. In this scenario, you probably gain more by going back to the stages of data extraction and preprocessing and rethink your decisions; it is better to have good data and a simple algorithm than poor data and a very complex algorithm. In particular, the data preparation phase consists of:
Exploratory data analysis
Variable selection
Identification and exclusion of outliers
Data aggregation
Inclusion criteria
Feature construction
Data partitioning
The machine learning phase consists of:
Patient stratification through unsupervised learning
k-means clustering
Patient classification through supervised learning
Feature selection
Logistic regression
Decision trees
Random forest
The first step is to import essential Python libraries and the MIMIC-III dataset.
Import libraries and data#
The next example shows the Python code that imports the following Python libraries:
ehrapy: package for electronic health record analysis with Python;
Numpy: fundamental package for scientific computing with Python. Provides a fast numerical array structure;
Pandas: provides high-performance, easy-to-use data structures and data analysis tools;
Matplotlib: basic plotting library;
IPython: for interactive data visualization.
[1]:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from IPython import display
import warnings
import seaborn as sns
import ehrapy as ep
import anndata as ad
plt.style.use("ggplot")
warnings.filterwarnings("ignore")
Installed version 0.4.0 of ehrapy is newer than the latest release 0.3.0! You are running a nightly version and features may break!
The next example shows the Python code that loads the data as an AnnData using ehrapy.io.read_csv. And we set icustay as the index column of .obs.
[2]:
adata = ep.io.read_csv("data.csv", index_column="icustay")
adata.obs["mortality_cat"] = adata[:, "mortality"].X
adata.obs["mortality_cat"] = adata.obs["mortality_cat"].astype(int).astype(str)
adata.obs["icustay"] = adata.obs.index.astype(int)
adata
2023-02-04 23:57:43,546 - root INFO - Added all columns to `obs`.
2023-02-04 23:57:44,015 - root INFO - Transformed passed dataframe into an AnnData object with n_obs x n_vars = `1258135` x `17`.
[2]:
AnnData object with n_obs × n_vars = 1258135 × 17
obs: 'mortality_cat', 'icustay'
uns: 'numerical_columns', 'non_numerical_columns'
layers: 'original'
[ ]:
data = adata.to_df()
data.index = data.index.astype(int)
Exploratory data analysis#
A quick preview of ‘data’ can be obtained using the ‘head’ function, which prints the first 5 rows of any given DataFrame:
[3]:
adata.to_df().head()
[3]:
| glasgow coma scale | glucose | heart rate | mean BP | oxygen saturation | respiratory rate | diastolic BP | systolic BP | temperature | height | pH | weight | hours | day | mortality | age | gender | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| icustay | |||||||||||||||||
| 206884 | 15.0 | NaN | 85.0 | NaN | 100.0 | 22.0 | NaN | NaN | NaN | NaN | NaN | NaN | 1.643333 | 1.0 | 0.0 | 51.126625 | 2.0 |
| 206884 | NaN | NaN | 89.0 | NaN | 98.0 | 21.0 | NaN | NaN | NaN | NaN | NaN | NaN | 2.643333 | 1.0 | 0.0 | 51.126625 | 2.0 |
| 206884 | NaN | NaN | 95.0 | NaN | 100.0 | 26.0 | NaN | NaN | NaN | NaN | NaN | NaN | 3.143333 | 1.0 | 0.0 | 51.126625 | 2.0 |
| 206884 | NaN | NaN | 93.0 | NaN | 100.0 | 30.0 | NaN | NaN | NaN | NaN | NaN | NaN | 3.643333 | 1.0 | 0.0 | 51.126625 | 2.0 |
| 206884 | NaN | NaN | 96.0 | NaN | 99.0 | 14.0 | NaN | NaN | NaN | NaN | NaN | NaN | 4.643333 | 1.0 | 0.0 | 51.126625 | 2.0 |
It tells us that the dataset contains information regarding patient demographics: age, gender, weight, height, mortality; physiological vital signs: diastolic blood pressure, systolic blood pressure, mean blood pressure, temperature, respiratory rate; lab tests: glucose, pH; scores: glasgow coma scale. Each observation/row is associated with a time stamp (column ‘hours’), indicating the number of hours since ICU admission where the observation was made. Each icustay has several observations for the same variable/column.
We can print the number of ICU stays by calculating the length of the unique indexes
[5]:
print(f"Number of ICU stays: {str(len(data.index.unique()))}")
print(f"Number of survivors: {str(len(data[data['mortality']==0].index.unique()))}")
print(f"Number of non-survivors: {str(len(data[data['mortality']==1].index.unique()))}")
print(
f"Mortality: {str(round(100*len(data[data['mortality']==1].index.unique()) / len(data.index.unique()),1))}%"
)
Number of ICU stays: 41496
Number of survivors: 37064
Number of non-survivors: 4432
Mortality: 10.7%
Next we run ep.pp.qc_metrics, which calculates various quality control metrics, to get number of missing data and summary statistics. The associated results can be shown as a table with ep.pl.qc_metrics.
[6]:
ep.pp.qc_metrics(adata)
ep.pl.qc_metrics(adata)
2023-02-04 23:58:05,788 - root INFO - Added the calculated metrics to AnnData's `obs` and `var`.
Ehrapy qc metrics of var ┏━━━━━━━━━━━━━┳━━━━━━━━━━━━━┳━━━━━━━━━━━━━┳━━━━━━━━━━━━━┳━━━━━━━━━━━━━┳━━━━━━━━━━━━━━┳━━━━━━━━━━━━━┳━━━━━━━━━━━━━━┓ ┃ Column name ┃ missing_va… ┃ missing_va… ┃ mean ┃ median ┃ standard_de… ┃ min ┃ max ┃ ┡━━━━━━━━━━━━━╇━━━━━━━━━━━━━╇━━━━━━━━━━━━━╇━━━━━━━━━━━━━╇━━━━━━━━━━━━━╇━━━━━━━━━━━━━━╇━━━━━━━━━━━━━╇━━━━━━━━━━━━━━┩ │ glasgow │ 976266.0 │ 77.5962833… │ 12.2318735… │ 15.0 │ 3.767215490… │ 3.0 │ 15.0 │ │ coma scale │ │ │ │ │ │ │ │ │ glucose │ 1194714.0 │ 94.9591260… │ 139.381622… │ 131.0 │ 52.18337249… │ 1.14999997… │ 1063.0 │ │ heart rate │ 217583.0 │ 17.2940900… │ 86.0076522… │ 85.0 │ 18.15764236… │ 0.0 │ 300.0 │ │ mean BP │ 722341.0 │ 57.4136320… │ 77.2334136… │ 75.6667022… │ 15.76190376… │ 0.0 │ 228.0 │ │ oxygen │ 259430.0 │ 20.6202037… │ 97.2340469… │ 98.0 │ 3.900190830… │ 0.0 │ 102.0 │ │ saturation │ │ │ │ │ │ │ │ │ respiratory │ 249870.0 │ 19.8603488… │ 18.9152641… │ 18.0 │ 5.932038784… │ 0.0 │ 130.0 │ │ rate │ │ │ │ │ │ │ │ │ diastolic │ 713406.0 │ 56.7034539… │ 58.5932540… │ 57.0 │ 15.70110511… │ 0.0 │ 222.0 │ │ BP │ │ │ │ │ │ │ │ │ systolic BP │ 712888.0 │ 56.6622818… │ 119.298118… │ 117.0 │ 23.42457771… │ 0.0 │ 300.0 │ │ temperature │ 1101284.0 │ 87.5330548… │ 37.0586204… │ 37.2000007… │ 1.477812528… │ 0.0 │ 46.5 │ │ height │ 1250088.0 │ 99.3604025… │ 168.680969… │ 170.0 │ 15.79851436… │ 0.0 │ 429.0 │ │ pH │ 1110883.0 │ 88.2960095… │ 7.36870145… │ 7.38000011… │ 0.084036871… │ 6.34999990… │ 7.929999828… │ │ weight │ 1240779.0 │ 98.6204978… │ 80.7241058… │ 77.3000030… │ 25.12936782… │ 1.0 │ 710.4000244… │ │ hours │ 0.0 │ 0.0 │ 19.1653347… │ 16.9452781… │ 13.67407894… │ 0.0 │ 48.0 │ │ day │ 0.0 │ 0.0 │ 1.35236442… │ 1.0 │ 0.477755039… │ 1.0 │ 3.0 │ │ mortality │ 0.0 │ 0.0 │ 0.13201762… │ 0.0 │ 0.338509976… │ 0.0 │ 1.0 │ │ age │ 0.0 │ 0.0 │ 73.9631958… │ 66.3408660… │ 52.22779083… │ 18.0205345… │ 310.2724304… │ │ gender │ 0.0 │ 0.0 │ 1.56987202… │ 2.0 │ 0.495093762… │ 1.0 │ 2.0 │ └─────────────┴─────────────┴─────────────┴─────────────┴─────────────┴──────────────┴─────────────┴──────────────┘
The dataset consists of 41,496 unique ICU stays and 1,258,135 observations. All columns with the exception of ‘hours’, ‘mortality’ and ‘day’ have missing information. Looking at the maximum and minimum values it is possible to spot the presence of outliers (e.g. max glucose). Both missing data and outliers are very common in ICU databases and need to be taken into consideration before applying ML algorithms.
Variable selection#
There should be a trade-off between the potential value of the variable in the model and the amount of data available. We already saw the amount of missing data for every column, but we still do not know how much information is missing at the patient level. In order to do so, we are going to aggregate data by ICU stay and look at the number of non-null values, using the ‘groupby’ function together with the ‘mean’ operator. This will give an indication of how many ICU stays have at least one observation for each variable.
Note that one patient might have multiple ICU stays. In this work, for the sake of simplicity, we will consider every ICU stay as an independent sample.
[7]:
adata_per_patient = ep.ad.df_to_anndata(data.groupby(["icustay"]).mean())
adata_per_patient
2023-02-04 23:58:06,112 - root INFO - Added all columns to `obs`.
2023-02-04 23:58:06,140 - root INFO - Transformed passed dataframe into an AnnData object with n_obs x n_vars = `41496` x `17`.
[7]:
AnnData object with n_obs × n_vars = 41496 × 17
uns: 'numerical_columns', 'non_numerical_columns'
layers: 'original'
We can easily use ep.pl.missing_values_barplot to visualize a bar chart of the null values:
[8]:
ep.pl.missing_values_barplot(adata_per_patient)
[8]:
<AxesSubplot: >
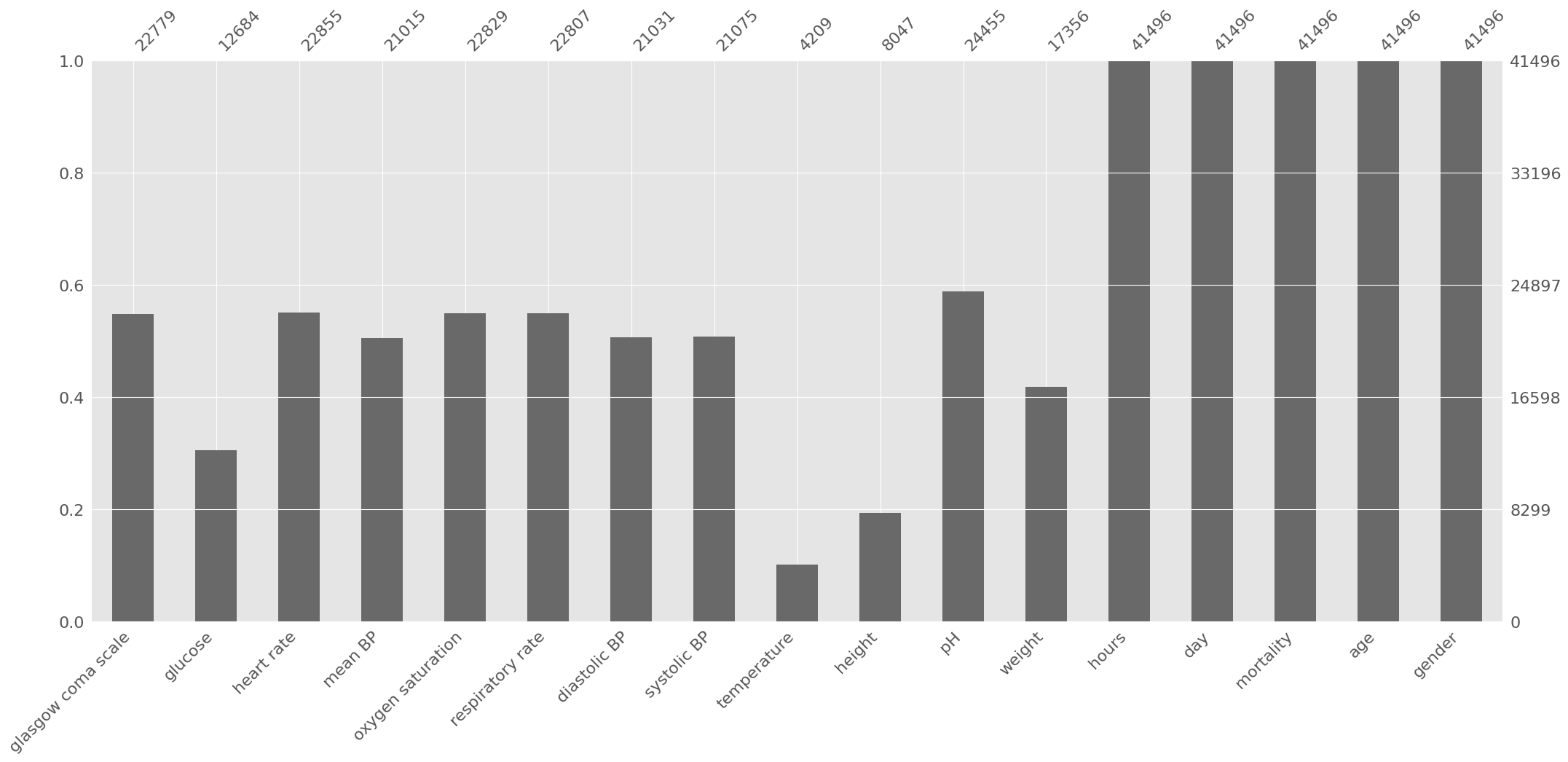
Based on the previous information, some decisions are made:
Height can be discarded due to the high amount of missing data;
Weight and height are typically used in combination (body mass index), since individually they typically provide low predictive power. Therefore, weight can also be discarded;
The other variables will be kept. Let us start with time-variant variables and set aside age and gender for now:
[9]:
variables = [
"diastolic BP",
"glasgow coma scale",
"glucose",
"heart rate",
"mean BP",
"oxygen saturation",
"respiratory rate",
"systolic BP",
"temperature",
"pH",
]
variables_mort = variables.copy()
variables_mort.append("mortality")
Data preprocessing#
Outliers#
Data visualization#
We already saw that outliers are present in the dataset, but we need to take a closer look at data before deciding how to handle them. Using ehrapy and its violin plot function we can easily create one boxplot for every variable.
[10]:
fig = plt.figure(figsize=(10, 10))
for i, variable in enumerate(variables, start=1):
ax = plt.subplot(4, 3, i)
ep.pl.violin(adata, keys=variable, ax=ax, show=False)
fig.tight_layout()
plt.show()
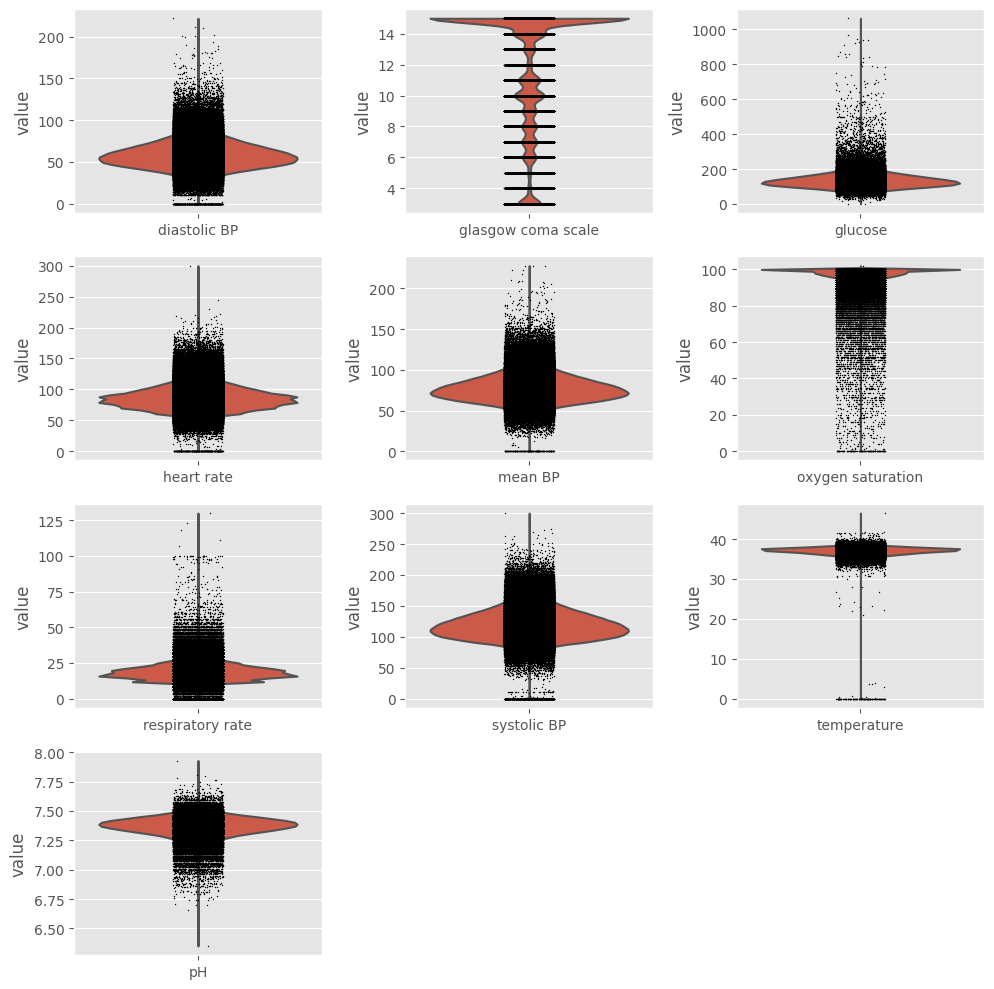
Exclusion#
Ideally, we should keep extreme values related to the patients’ poor health condition and exclude impossible values (such as negative temperature) and probable outliers (such as heart rate above 250 beats/min). In order to do so, values that fall outside boundaries defined by expert knowledge are excluded. This way, we avoid excluding extreme (but correct/possible) values. We can use ep.pp.qc_lab_measurements function to examine lab measurements for reference ranges and outliers. To do so,
we need to define a custom reference table which contains possible values for each measurement.
[11]:
measurements = [
"diastolic BP",
"systolic BP",
"mean BP",
"glucose",
"heart rate",
"respiratory rate",
"temperature",
"pH",
"oxygen saturation",
]
reference_table = pd.DataFrame(
np.array(
[
"<300",
"<10000",
"0-300",
"<2000",
"<400",
"<300",
"20-50",
"6.8-7.8",
"0-100",
]
),
columns=["Traditional Reference Interval"],
index=measurements,
)
reference_table
[11]:
| Traditional Reference Interval | |
|---|---|
| diastolic BP | <300 |
| systolic BP | <10000 |
| mean BP | 0-300 |
| glucose | <2000 |
| heart rate | <400 |
| respiratory rate | <300 |
| temperature | 20-50 |
| pH | 6.8-7.8 |
| oxygen saturation | 0-100 |
[12]:
ep.pp.qc_lab_measurements(
adata, measurements=measurements, reference_table=reference_table
)
nulls_before = adata.to_df().isnull().sum().sum()
for measurement in measurements:
adata[~adata.obs[f"{measurement} normal"], measurement].X = np.nan
nulls_now = adata.to_df().isnull().sum().sum()
print(f"Number of observations removed: {str(nulls_now - nulls_before)}")
print(
f"Observations corresponding to outliers: {str(round((nulls_now - nulls_before)*100/adata.n_obs,2))}%"
)
Number of observations removed: 194
Observations corresponding to outliers: 0.02%
Data visualization after outliers exclusion#
The same code can be used to verify the data distribution after exclusion of outliers. The ep.pl.violin function allows to visualize the underlying distribution and the number of observations. Setting groupby = "mortality_cat" shows the plots partitioned by outcome.
[14]:
fig = plt.figure(figsize=(10, 10))
for i, variable in enumerate(variables, start=1):
ax = plt.subplot(4, 3, i)
ep.pl.violin(
adata,
keys=variable,
groupby="mortality_cat",
ax=ax,
show=False,
stripplot=False,
)
fig.tight_layout()
plt.show()
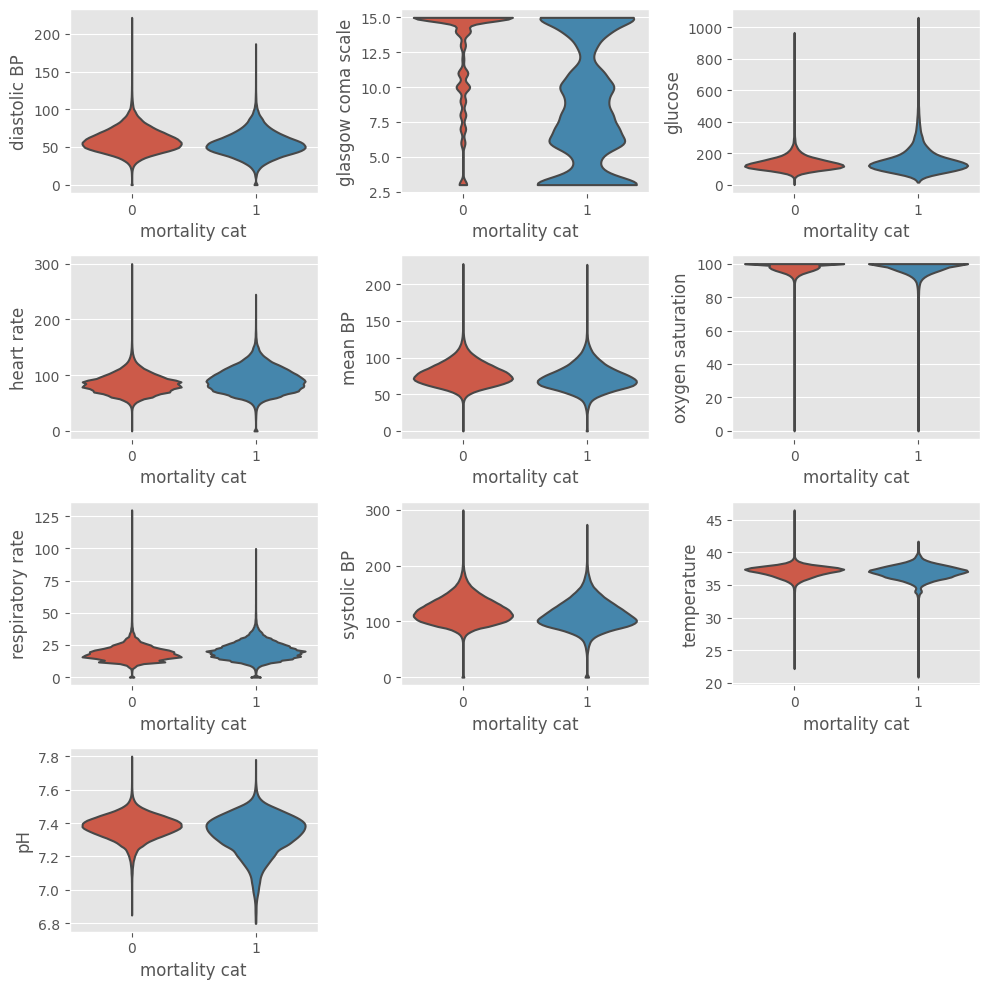
Aggregate data by hour#
As mentioned before, the dataset contains information regarding the first 2 days in the ICU. Every observation is associated with a time stamp, indicating the number of hours elapsed between ICU admission and the time when the observation was collected (e.g., 0.63 hours). To allow for ease of comparison, individual data is condensed into hourly observations by selecting the median value of the available observations within each hour. First, the ‘floor’ operator is applied in order to categorize the hours in 48 bins (hour 0, hour 1, …, hour 47). Then, the ‘groupby’ function with the ‘median’ operator is applied in order to get the median heart rate for each hour of each ICU stay:
[16]:
adata.obs["hour"] = np.floor(adata[:, "hours"].X)
# data goes until h = 48, change 48 to 47
adata.obs["hour"][adata.obs["hour"] == 48] = 47
data_median_hour = (
ep.ad.anndata_to_df(adata, obs_cols=["hour", "icustay"])
.groupby(["icustay", "hour"])[variables_mort]
.median()
)
2023-02-04 23:58:52,006 - root INFO - Added `['hour', 'icustay']` columns to `X`.
The ‘groupby’ will create as many indexes as groups defined. In order to facilitate the next operations, a single index is desirable. In the next example, the second index (column ‘hour’) is excluded and kept as a DataFrame column. Note that the first index corresponds to level 0 and second index to level 1. Therefore, in order to exclude the second index and keep it as a column, ‘level’ should be set to 1 and ‘drop’ to False.
[17]:
data_median_hour = data_median_hour.reset_index(level=(1), drop=False)
The next example shows the vital signs for a specific ICU stay (ID = 267387). Consecutive hourly observations are connected by line.
[18]:
vitals = [
"diastolic BP",
"heart rate",
"mean BP",
"oxygen saturation",
"respiratory rate",
"systolic BP",
"temperature",
]
ICUstayID = 267387
fig, ax = plt.subplots(figsize=(20, 6))
# scatter plot
for col in vitals:
ax.scatter(
data_median_hour.loc[ICUstayID, "hour"], data_median_hour.loc[ICUstayID, col]
)
plt.legend(
vitals, loc=9, bbox_to_anchor=(0.5, -0.1), ncol=len(vitals), prop={"size": 14}
)
plt.xticks(np.arange(0, 49, step=1))
plt.xlabel("Hours since ICU admission")
# connect consecutive points by line
for col in vitals:
ax.plot(
data_median_hour.loc[ICUstayID, "hour"], data_median_hour.loc[ICUstayID, col]
)
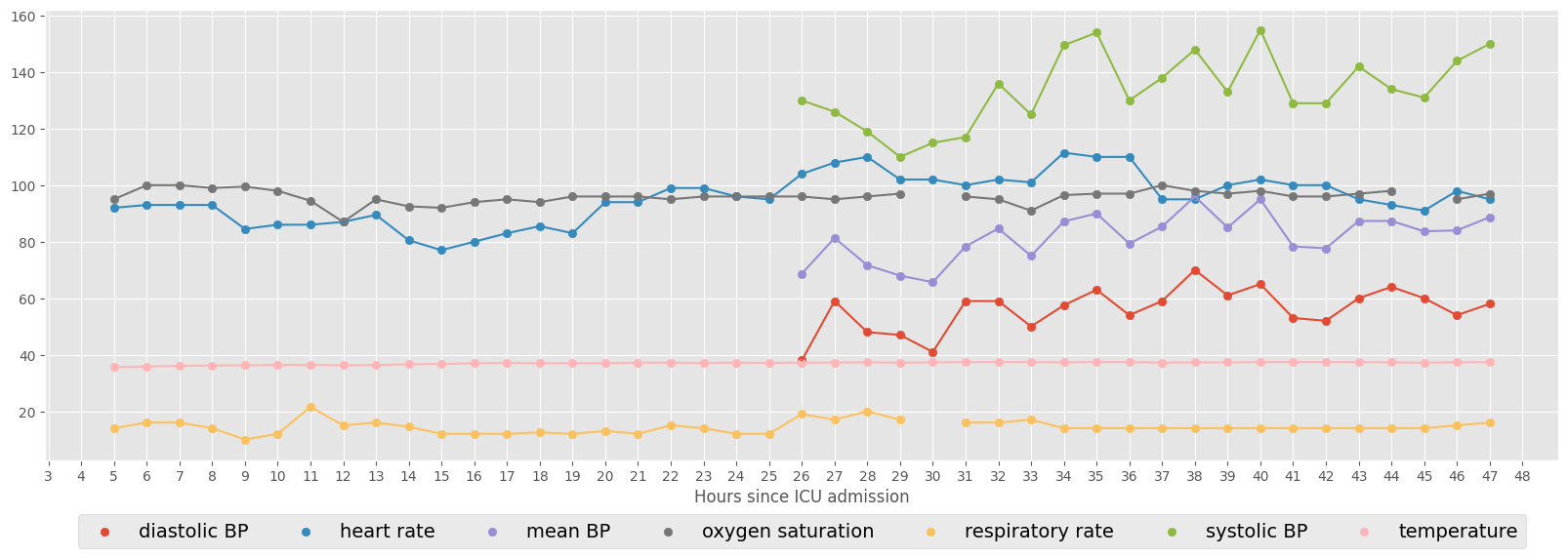
Select minimum number of observations#
We decided to keep all time-variant variables available. However, and as you can see in the previous example, since not all variables have an hourly sampling rate, a lot of information is missing (coded as NaN). In order to train ML algorithms it is important to decide how to handle the missing information. Two options are: to replace the missing information with some value or to exclude the missing information. In this work, we will avoid introducing bias resultant from replacing missing values with estimated values (which is not the same as saying that this is not a good option in some situations). Instead, we will focus on a complete case analysis, i.e., we will include in our analysis only those patients who have complete information.
Depending on how we will create the feature set, complete information can have different meanings. For example, if we want to use one observation for every hour, complete information is to have no missing data for every t=0 to t=47, which would lead to the exclusion of the majority of data. In order to reduce the size of the feature space, one common approach is to use only some portions of the time series. This is the strategy that will be followed in this work. Summary statistics, including the mean, maximum, minimum and standard deviation will be used to extract relevant information from the time series. In this case, it is important to define the minimum length of the time series before starting to select portions of it. One possible approach is to use all patients who have at least one observation per variable. Since, the summary statistics have little meaning if only one observation is available, a threshold of two observations will be used.
In the following function, setting ‘min_num_meas = 2’ means that we are selecting ICU stays where each variable was recorded at least once at two different hours. Again, we are using the ‘groupby’ function to aggregate data by ICU stay, and the ‘count’ operator to count the number of observations for each variable. We then excluded ICU stays where some variable was recorded less than 2 times. Later on this chapter we will show how to extract features from the time series, in order to reduce the size of the feature space.
[19]:
min_num_meas = 2
def extr_min_num_meas(data_median_hour, min_num_meas):
"""Select ICU stays where there are at least 'min_num_meas' observations
and print the resulting DataFrame size"""
data_count = data_median_hour.groupby(["icustay"])[variables_mort].count()
for col in data_count:
data_count[col] = data_count[col].apply(
lambda x: np.nan if x < min_num_meas else x
)
data_count = data_count.dropna(axis=0, how="any")
print(f"Number of ICU stays: {str(data_count.shape[0])}")
print(f"Number of features: {str(data_count.shape[1])}")
unique_stays = data_count.index.unique()
data_median_hour = data_median_hour.loc[unique_stays]
return data_median_hour
data_median_hour = extr_min_num_meas(data_median_hour, min_num_meas)
Number of ICU stays: 2410
Number of features: 11
It is always important to keep track of the size of data while making decisions about inclusion/exclusion criteria. We started with a database of around 60,000 ICU stays, imported a fraction of those that satisfied some criteria, in a total of 41,496 ICU stays, and are now looking at 2,410 ICU stays.
Exploratory (preprocessed-)data analysis#
Pairwise plotting#
One of the most used techniques in exploratory data analysis is the pairs plot (also called scatterplot). This technique allows to see both the distribution of single variables as well as relationships between every two variables. It is easily implemented in Python using the ‘seaborn’ library. The next example shows how to plot the pairwise relationships between variables and the histograms of single variables partitioned by outcome (survival vs non-survival). The parameter ‘vars’ is used to indicate the set of variables to plot and ‘hue’ to indicate the use of different markers for each level of the hue variable. A subset of data is used: ‘dropna(axis=0, how=’any’)’ will exclude all rows containing missing information.
[20]:
sns.set(style="ticks")
g = sns.pairplot(
data_median_hour[variables_mort].dropna(axis=0, how="any"),
vars=variables,
hue="mortality",
)
# hide the upper triangle
for i, j in zip(*np.triu_indices_from(g.axes, 1)):
g.axes[i, j].set_visible(False)
plt.show()
# change back to our preferred style
plt.style.use("ggplot")
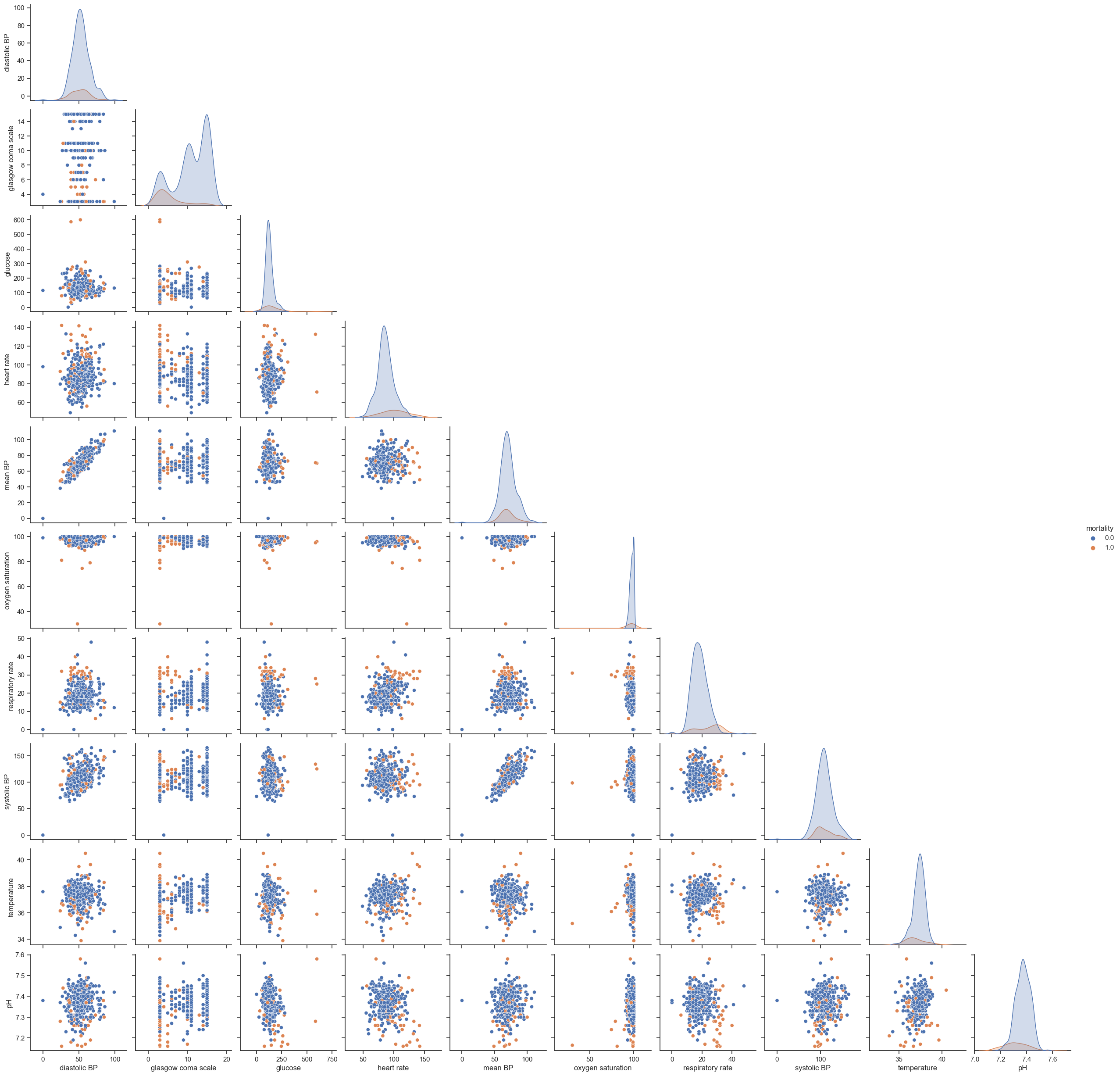
Unfortunately, this type of plot only allows to see relationships in a 2D space, which in most cases is not enough to find any patterns or trends. Nonetheless, it is still able to tell us important aspects of data; if not for showing promising directions for data analysis, to provide a means to check data’s integrity. Things to highlight are:
Hypoxic patients generally have lower SBPs;
SBP correlates with MAP, which is a nice test of the data’s integrity;
Fever correlates with increasing tachycardia, also as expected.
Time series ploting#
In order to investigate time trends, it is useful to visualize the mean HR partitioned by outcome from t=0 to t=47. In order to easily perform this task, the DataFrame needs to be restructured.
The next function takes as input a pandas DataFrame and the name of the variable and transposes/pivots the DataFrame in order to have columns corresponding to time (t=0 to t=47) and rows corresponding to ICU stays. If ‘filldata’ is set to 1, the function will fill missing information using the forward fill method, where NaNs are replaced by the value preceding it. In case no value is available for forward fill, NaNs are replaced by the next value in the time series. The function ‘fillna’ with the method parameter set to ‘ffill’ and ‘bfill’, allows us to easily perform these two actions. If ‘filldata’ is set to 0 no missing data imputation is performed.
[21]:
def timeseries_data(data_median_hour, variable, filldata=1):
"""Return matrix of time series data for clustering,
with rows corresponding to unique observations (ICU stays) and
columns corresponding to time since ICU admission"""
data4clustering = data_median_hour.pivot(columns="hour", values=variable)
if filldata == 1:
# first forward fill
data4clustering = data4clustering.fillna(method="ffill", axis=1)
# next backward fill
data4clustering = data4clustering.fillna(method="bfill", axis=1)
data4clustering = data4clustering.dropna(axis=0, how="all")
return data4clustering
The next script plots the average HR for every variable in the dataset. At this point, ‘filldata’ is set to 0.
[22]:
fig = plt.figure(figsize=(10, 10))
count = 0
for variable in variables:
count += 1
data4clustering = timeseries_data(data_median_hour, variable, filldata=0)
print(
f"Plotting {str(data4clustering.count().sum())} observations from {str(data4clustering.shape[0])} ICU stays - {variable}"
)
class1 = data4clustering.loc[
data_median_hour[data_median_hour["mortality"] == 1].index.unique()
].mean()
class0 = data4clustering.loc[
data_median_hour[data_median_hour["mortality"] == 0].index.unique()
].mean()
plt.subplot(4, 3, count)
plt.plot(class1)
plt.plot(class0)
plt.xlabel("Hours since ICU admission")
plt.ylabel("Mean " + variable)
fig.tight_layout()
plt.legend(["Non-survivors", "Survivors"])
plt.show()
Plotting 25937 observations from 2410 ICU stays - diastolic BP
Plotting 26598 observations from 2410 ICU stays - glasgow coma scale
Plotting 18193 observations from 2410 ICU stays - glucose
Plotting 91304 observations from 2410 ICU stays - heart rate
Plotting 25675 observations from 2410 ICU stays - mean BP
Plotting 88387 observations from 2410 ICU stays - oxygen saturation
Plotting 90063 observations from 2410 ICU stays - respiratory rate
Plotting 25971 observations from 2410 ICU stays - systolic BP
Plotting 59148 observations from 2410 ICU stays - temperature
Plotting 25143 observations from 2410 ICU stays - pH
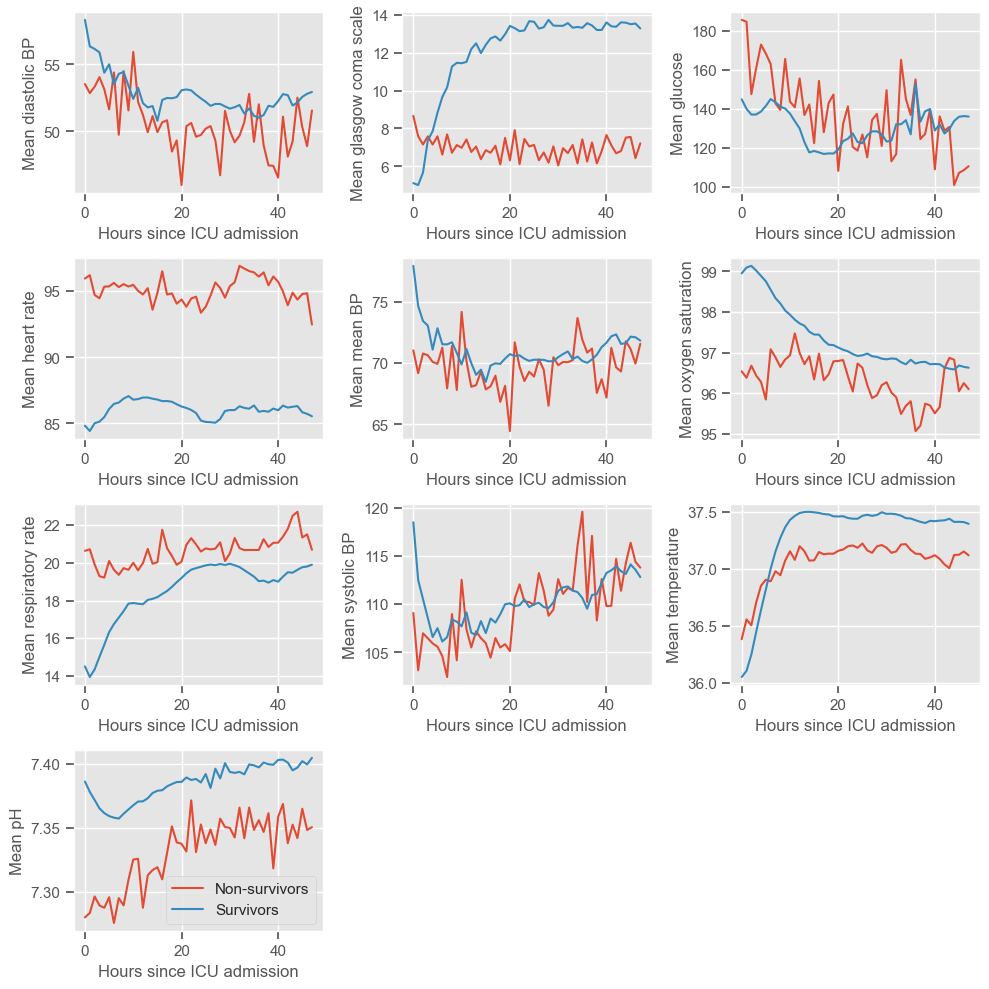
The physiological deterioration or improvement over time is very different between survivors and non-survivors. While using the pairwise plot we could not see any differences between the groups, this type of plot reveals very clear differences. Several observations can be made:
Diastolic BP
higher in the survival group
rapidly decreasing during the first 10 hours, especially in the survival group, and increasing at a lower rate thereafter
Glasgow coma scale
higher in the survival group, increasing over time
steady around 8 in the non-survival group
similar between both groups at admission, but diverging thereafter
Glucose
decreasing over time in both groups
Heart rate
lower in the survival group
Mean BP - similar to diastolic BP
Oxygen saturation
higher in the survival group
low variation from t=0 to t=48h
Respiratory rate
lower in the survival group, slowly increasing over time
steady around 20 in the non-survival group
Systolic BP - similar to diastolic and mean BP
Temperature
low variation from t=0 to t=48h
slightly increasing during the first 10 hours
pH
Increasing over time in both groups
pH < 7.35 (associated with metabolic acidosis) during the first 10 hours in the non-survival group
Most of these graphs have fairly interesting trends, but we would not consider the oxygen saturation or temperature graphs to be clinically relevant.
Feature construction#
The next step before ML is to extract relevant features from the time series. As already mentioned, the complete time series could be used for ML, however, missing information would have to be filled or excluded. Also, using the complete time series would result in (48 \text{hours}\times 11 :nbsphinx-math:`text{variables}`=528) features, which would make the models difficult to interpret and could lead to overfitting. There is a simpler solution, which is to use only a portion of the information available, ideally the most relevant information for the prediction task.
Feature construction addresses the problem of finding the transformation of variables containing the greatest amount of useful information. In this chapter, simple operations will be used to construct/extract important features from the time series:
Maximum
Minimum
Standard deviation
Mean
These features summarize the worst, best, variation and average patient condition from t=0 to t=47h. In the proposed exercises you will do this for each day separately, which will increase the dataset dimensionality but hopefully will allow the extraction of more useful information.
Using the ‘groupby’ function to aggregate data by ICU stay, together with the ‘max’, ‘min’, ‘std’ and ‘mean’ operators, these features can be easily extracted:
[23]:
def feat_transf(data):
data_max = data.groupby(["icustay"])[variables].max()
data_max.columns = ["max " + str(col) for col in data_max.columns]
data_min = data.groupby(["icustay"])[variables].min()
data_min.columns = ["min " + str(col) for col in data_min.columns]
data_sd = data.groupby(["icustay"])[variables].std()
data_sd.columns = ["sd " + str(col) for col in data_sd.columns]
data_mean = data.groupby(["icustay"])[variables].mean()
data_mean.columns = ["mean " + str(col) for col in data_mean.columns]
data_agg = pd.concat([data_min, data_max, data_sd, data_mean], axis=1)
return data_agg
data_transf = feat_transf(data_median_hour).dropna(axis=0)
print("Extracted features: ")
display.display(data_transf.columns)
print("")
print(f"Number of ICU stays: {str(data_transf.shape[0])}")
print(f"Number of features: {str(data_transf.shape[1])}")
Extracted features:
Index(['min diastolic BP', 'min glasgow coma scale', 'min glucose',
'min heart rate', 'min mean BP', 'min oxygen saturation',
'min respiratory rate', 'min systolic BP', 'min temperature', 'min pH',
'max diastolic BP', 'max glasgow coma scale', 'max glucose',
'max heart rate', 'max mean BP', 'max oxygen saturation',
'max respiratory rate', 'max systolic BP', 'max temperature', 'max pH',
'sd diastolic BP', 'sd glasgow coma scale', 'sd glucose',
'sd heart rate', 'sd mean BP', 'sd oxygen saturation',
'sd respiratory rate', 'sd systolic BP', 'sd temperature', 'sd pH',
'mean diastolic BP', 'mean glasgow coma scale', 'mean glucose',
'mean heart rate', 'mean mean BP', 'mean oxygen saturation',
'mean respiratory rate', 'mean systolic BP', 'mean temperature',
'mean pH'],
dtype='object')
Number of ICU stays: 2410
Number of features: 40
A DataFrame containing one row per ICU stay was obtained, where each column corresponds to one feature. We are one step closer to building the models. Next, we are going to add the time invariant information - age and gender - to the dataset.
[24]:
mortality = data.loc[data_transf.index]["mortality"].groupby(["icustay"]).mean()
age = data.loc[data_transf.index]["age"].groupby(["icustay"]).mean()
gender = data.loc[data_transf.index]["gender"].groupby(["icustay"]).mean()
data_transf_inv = pd.concat([data_transf, age, gender, mortality], axis=1).dropna(
axis=0
)
print(f"Number of ICU stays: {str(data_transf_inv.shape[0])}")
print(f"Number of features: {str(data_transf_inv.shape[1])}")
Number of ICU stays: 2410
Number of features: 43
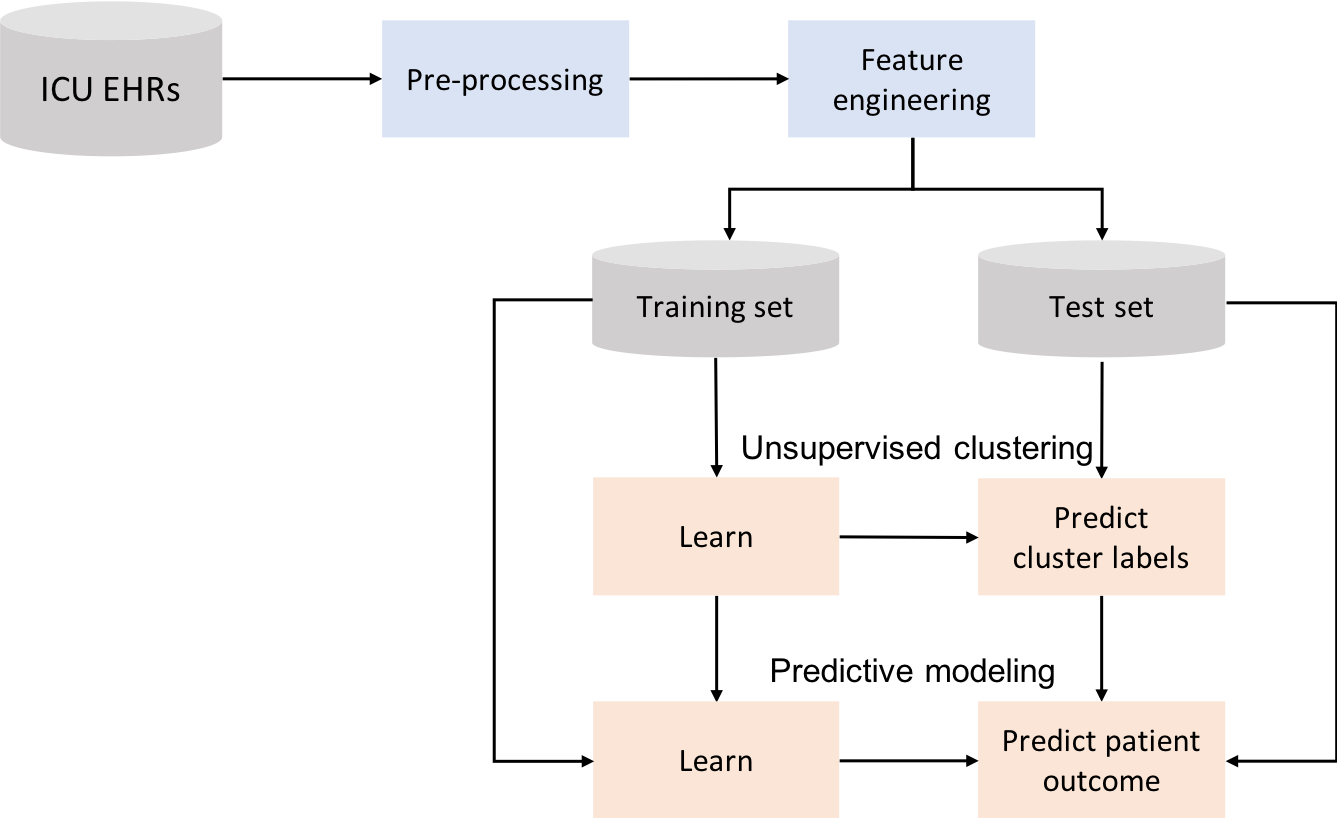
Data partitioning#
In order to assess the performance of the models, data can be divided into training, test and validation sets as exemplified in the Figure. This is known as the holdout validation method.
Training set: used to train/build the learning algorithm.
Validation (or development) set: use to tune parameters, select features, and make other decisions regarding the learning algorithm.
Test set: used to evaluate the performance of the algorithm, but not to make any decisions regarding the learning algorithm architecture or parameters.
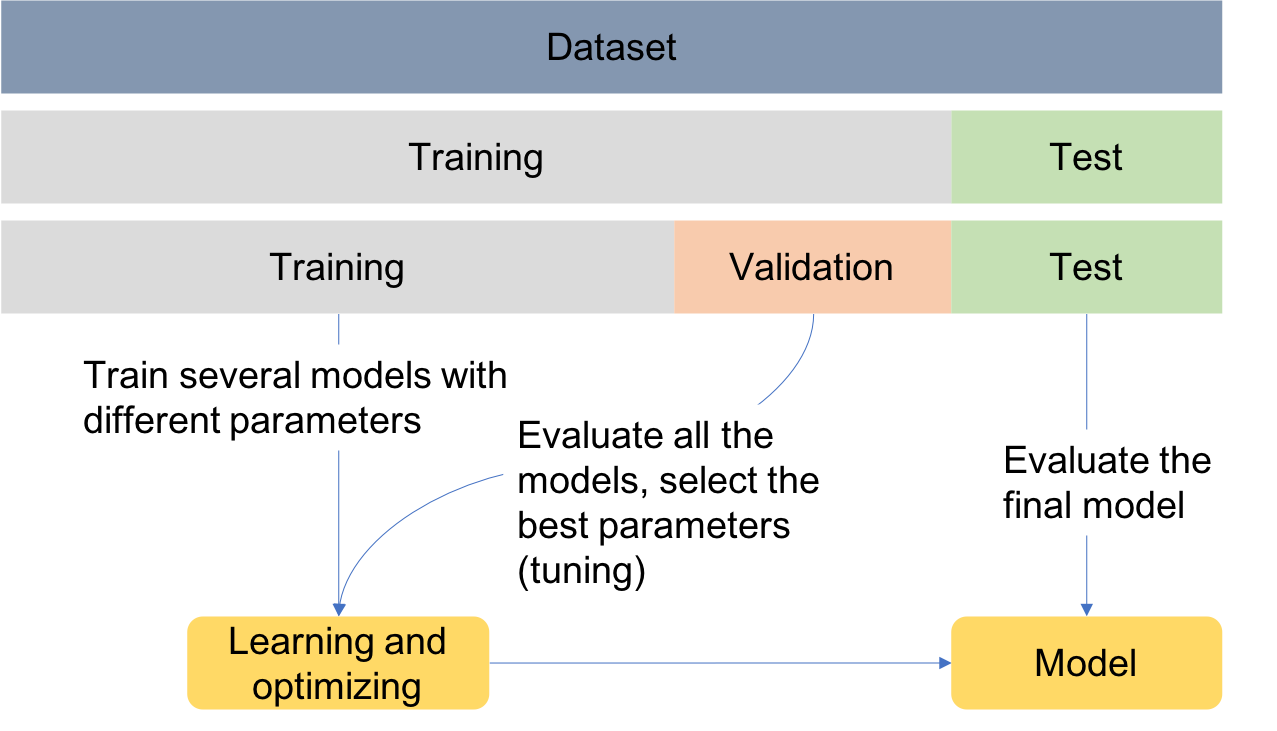
For simplicity, data is divided into two sets, one for training and another for testing. Later, when performing feature selection, the training set will be divided into two sets, for training and validation.
Scikit-learn (sklearn) is the essential machine learning package in Python. It provides simple and efficient tools for data mining and data analysis. The next example shows how to use the train_test_split function from sklearn library to randomly assign observations to each set. The size of the sets can be controlled using the test_size parameter, which defines the size of the test set and which in this case is set to 20%. When using the train_test_split function, it is
important to set the random_state parameter so that later the same results can be reproduced.
[25]:
from sklearn.model_selection import train_test_split
# set the % of observations in the test set
test_size = 0.2
# Divide the data intro training and test sets
X_train, X_test, y_train, y_test = train_test_split(
data_transf_inv,
data_transf_inv[["mortality"]],
test_size=test_size,
random_state=10,
)
It is useful to create a function that prints the size of data in each set:
[26]:
def print_size(y_train, y_test):
print(
f"{str(len(y_train[y_train['mortality']==1]))} ( {str(round(len(y_train[y_train['mortality']==1])/len(y_train)*100,1))}%) non-survivors in training set"
)
print(
f"{str(len(y_train[y_train['mortality']==0]))} ( {str(round(len(y_train[y_train['mortality']==0])/len(y_train)*100,1))}%) survivors in training set"
)
print(
f"{str(len(y_test[y_test['mortality']==1]))} ( {str(round(len(y_test[y_test['mortality']==1])/len(y_test)*100,1))}%) non-survivors in test set"
)
print(
f"{str(len(y_test[y_test['mortality']==0]))} ( {str(round(len(y_test[y_test['mortality']==0])/len(y_test)*100,1))}%) survivors in test set"
)
In cases where the data is highly imbalanced, it might be a good option to force an oversampling of the minority class, or an undersampling of the majority class so that the model is not biased towards the majority class. This should be performed on the training set, whereas the test set should maintain the class imbalance found on the original data, so that when evaluating the final model a true representation of data is used.
For the purpose of facilitating clustering interpretability, undersampling is used. However, as a general rule of thumb, and unless the dataset contains a huge number of observations, oversampling is preferred over undersampling because it allows keeping all the information in the training set. In any case, selecting learning algorithms that account for class imbalance might be a better choice.
The next example shows how to undersample the majority class, given a desired size of the minority class, controlled by the parameter ‘perc_class1’. If ‘perc_class1’>0, undersampling is performed in order to have a balanced training set. If ‘perc_class1’=0, no balancing is performed.
[27]:
# set the % of class 1 samples to be present in the training set.
perc_class1 = 0.4
print("Before balancing")
print_size(y_train, y_test)
if perc_class1 > 0:
# Find the indices of class 0 and class 1 samples
class0_indices = y_train[y_train["mortality"] == 0].index
class1_indices = y_train[y_train["mortality"] == 1].index
# Calculate the number of samples for the majority class (survivors)
class0_size = round(
np.int(
(len(y_train[y_train["mortality"] == 1]) * (1 - perc_class1)) / perc_class1
),
0,
)
# Set the random seed generator for reproducibility
np.random.seed(10)
# Random sample majority class indices
random_indices = np.random.choice(class0_indices, class0_size, replace=False)
# Concat class 0 with class 1 indices
X_train = pd.concat([X_train.loc[random_indices], X_train.loc[class1_indices]])
y_train = pd.concat([y_train.loc[random_indices], y_train.loc[class1_indices]])
print("After balancing")
print_size(y_train, y_test)
# Exclude output from input data
X_train = X_train.drop(columns="mortality")
X_test = X_test.drop(columns="mortality")
Before balancing
107 ( 5.5%) non-survivors in training set
1821 ( 94.5%) survivors in training set
31 ( 6.4%) non-survivors in test set
451 ( 93.6%) survivors in test set
After balancing
107 ( 40.1%) non-survivors in training set
160 ( 59.9%) survivors in training set
31 ( 6.4%) non-survivors in test set
451 ( 93.6%) survivors in test set
Clustering#
Clustering is a learning task that aims at decomposing a given set of observations into subgroups (clusters), based on data similarity, such that observations in the same cluster are more closely related to each other than observations in different clusters. It is an unsupervised learning task, since it identifies structures in unlabeled datasets, and a classification task, since it can give a label to observations according to the cluster they are assigned to.
This work focuses on the following questions:
Can we identify distinct patterns even if the class labels are not provided?
How are the different patterns represented across different outcomes?
In order to address these questions, we will start by providing a description of the basic concepts underlying k-means clustering, which is the most well known and simple clustering algorithm. We will show how the algorithm works using 2D data as an example, perform clustering of time series and use the information gained with clustering to train predictive models. The k-means clustering algorithm is described next:
K-means clustering algorithm#
Consider a (training) dataset composed of \(N\) observations:
Initialize K centroids \(\mu_1, \mu_2, ..., \mu_K\) randomly.
Repeat until convergence:
Cluster assignment
Assign each \(x_i\) to the nearest cluster. For every \(i\) do:
\[\begin{aligned} \underset{j}{argmin}\left \| x_i-\mu_j \right \|^2, \end{aligned}\]where \(j=1,2,...,K\)
Cluster updating
Update the cluster centroids \(\mu_j\). For every \(j\) do:
\[\begin{aligned} \mu_j = \frac{1}{N_j}\left [ x_1^j + x_2^j + ... + x_{N_j}^j \right ], \end{aligned}\]where \(N_j\) is the number of observations assigned to cluster \(j\), \(k=1,2, ..., N_j\), and \(x_k^j\) represents observation \(k\) assigned to cluster \(j\). Each new centroid corresponds the mean of the observations assigned in the previous step.
Exemplification with 2D data#
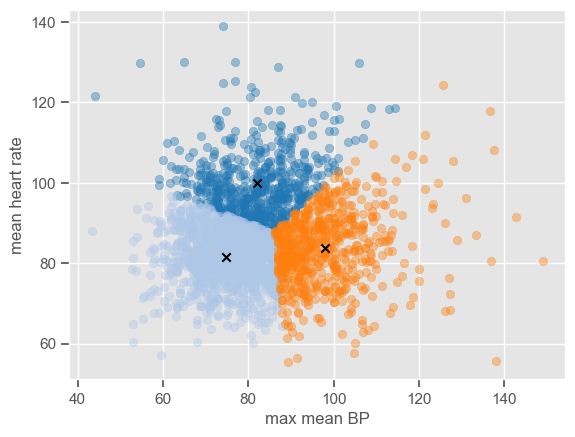
Although pairwise plots did not reveal any interesting patterns, some clusters might have emerged after the data were transformed. You can re-run the code for pairwise plots between transformed features, but note that it will be time consuming due to the high dimensionality of the dataset. Features ‘max mean BP’ and ‘mean heart rate’ were chosen for illustrative purposes. The dataset is plotted below:
[28]:
x1 = "max mean BP"
x2 = "mean heart rate"
sns.lmplot(data=data_transf_inv, x=x1, y=x2, hue="mortality", fit_reg=False);
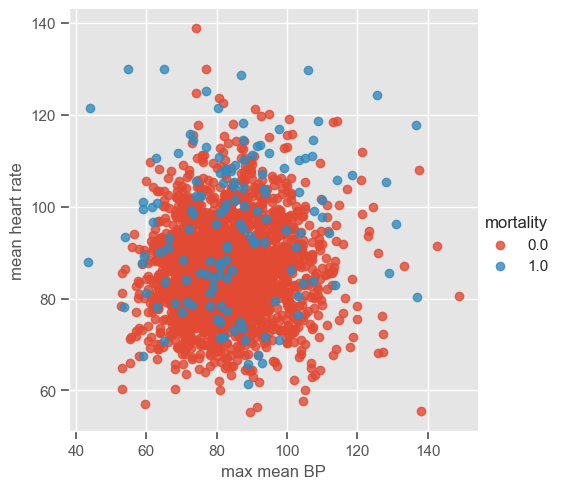
The number of clusters (K) must be provided before running k-means. It is not easy to guess the number of clusters just by looking at the previous plot, but for the purpose of understanding how the algorithm works 3 clusters are used. As usual, the ‘random_state’ parameter is predefined. Note that it does not matter which value is defined; the important thing is that this way we guarantee that when using the predefined value we will always get the same results.
The next example shows how to perform k-means using ‘sklearn’.
[29]:
from sklearn.cluster import KMeans
# set the number of clusters
K = 3
# input data to fit K-means
X = pd.DataFrame.to_numpy(data_transf_inv[[x1, x2]])
# fit kmeans
kmeans = KMeans(n_clusters=K, random_state=0).fit(data_transf_inv[[x1, x2]])
The attribute ‘labels_’ gives the cluster labels indicating to which cluster each observation belongs, and ‘cluster_centers_’ gives the coordinates of cluster centers representing the mean of all observations in the cluster. Using these two attributes it is possible to plot the clusters centers and the data in each cluster using different colors do distinguish the clusters:
[30]:
classes = kmeans.labels_
centroids = kmeans.cluster_centers_
# define a colormap
colormap = plt.get_cmap("tab20")
for c in range(K):
centroids[c] = np.mean(X[classes == c], 0)
plt.scatter(x=X[classes == c, 0], y=X[classes == c, 1], alpha=0.4, c=colormap(c))
plt.scatter(x=centroids[c, 0], y=centroids[c, 1], c="black", marker="x")
plt.xlabel(x1)
plt.ylabel(x2)
display.clear_output(wait=True)
The algorithm is simple enough to be implemented using a few lines of code. If you want to see how the centers converge after a number of iterations, you can use the code below which is an implementation of the k-means clustering algorithm step by step.
[31]:
# The following code was adapted from http://jonchar.net/notebooks/k-means/
import time
from IPython import display
K = 3
def initialize_clusters(points, k):
"""Initializes clusters as k randomly selected coordinates."""
return points[np.random.randint(points.shape[0], size=k)]
def get_distances(centroid, points):
"""Returns the distance between centroids and observations."""
return np.linalg.norm(points - centroid, axis=1)
# Initialize centroids
centroids = initialize_clusters(X, K)
centroids_old = np.zeros([K, X.shape[1]], dtype=np.float64)
# Initialize the vectors in which the assigned classes
# of each observation will be stored and the
# calculated distances from each centroid
classes = np.zeros(X.shape[0], dtype=np.float64)
distances = np.zeros([X.shape[0], K], dtype=np.float64)
# Loop until convergence of centroids
error = 1
while error > 0:
# Assign all observations to the nearest centroid
for i, c in enumerate(centroids):
distances[:, i] = get_distances(c, X)
# Determine class membership of each observation
# by picking the closest centroid
classes = np.argmin(distances, axis=1)
# Update centroid location using the newly
# assigned observations classes
# Change to median in order to have k-medoids
for c in range(K):
centroids[c] = np.mean(X[classes == c], 0)
plt.scatter(
x=X[classes == c, 0], y=X[classes == c, 1], alpha=0.4, c=colormap(c)
)
plt.scatter(x=centroids[c, 0], y=centroids[c, 1], c="black", marker="x")
error = sum(get_distances(centroids, centroids_old))
centroids_old = centroids.copy()
# pl.text(max1, min2, str(error))
plt.xlabel(x1)
plt.ylabel(x2)
display.clear_output(wait=True)
display.display(plt.gcf())
time.sleep(0.01)
plt.gcf().clear()
<Figure size 640x480 with 0 Axes>
The plot shows the position of the cluster centers at each iteration, until convergence to the final centroids. Note that the trajectory of the centers depends on the cluster initialization; because the initialization is random, the centers might not always converge to the same position.
Time series clustering#
Time series analysis revealed distinct and interesting patterns across survivors and non-survivors. Next, K-means clustering will be used to investigate patterns in time series. The goal is to stratify patients according to their evolution in the ICU, from admission to t=48 hours, for every variable separately. Note that at this point we are back working with time series information instead of constructed features.
For this particular task and type of algorithm, it is important to normalize data for each patient separately. This will allow a comparison between time trends rather than a comparison between the magnitude of observations. In particular, if the data is normalized individually for each patient, clustering will tend to group together patients that (for example) started with the lowest values and ended up with the highest values, whereas if the data is not normalized, the same patients might end up in different clusters because of the magnitude of the signal, even though the trend is similar.
Missing data is filled forward, i.e., missing values are replaced with the value preceding it (the last known value at any point in time). If there is no information preceding a missing value, these are replaced by the following values.
[32]:
# Now we are going to pivot the table in order to have rows corresponding to unique
# ICU stays and columns corresponding to hour since admission. This will be used for clustering
def clustering(variable, ids_clustering, K, *args):
"""Return data for clustering, labels attributted to training observations and
if *args is provided return labels attributted to test observations"""
data4clustering = timeseries_data(data_median_hour, variable, filldata=1)
# data for clustering is normalized by patient
# since the data is normalized by patient we can normalize training and test data together
for index, row in data4clustering.iterrows():
maxx = data4clustering.loc[index].max()
minn = data4clustering.loc[index].min()
data4clustering.loc[index] = (data4clustering.loc[index] - minn) / (maxx - minn)
# select data for creating the clusters
data4clustering_train = data4clustering.loc[ids_clustering].dropna(axis=0)
print(
"Using "
+ str(data4clustering_train.shape[0])
+ " ICU stays for creating the clusters"
)
# create the clusters
kmeans = KMeans(n_clusters=K, random_state=2).fit(data4clustering_train)
centers = kmeans.cluster_centers_
labels = kmeans.labels_
# test the clusters if test data is provided
labels_test = []
for arg in args:
data4clustering_test = data4clustering.loc[arg].set_index(arg).dropna(axis=0)
labels_test = kmeans.predict(data4clustering_test)
labels_test = pd.DataFrame(labels_test).set_index(data4clustering_test.index)
print(
"Using "
+ str(data4clustering_test.shape[0])
+ " ICU stays for cluster assignment"
)
print(str(K) + " clusters")
cluster = 0
d = {}
mortality_cluster = {}
colormap1 = plt.get_cmap("jet")
colors = colormap1(np.linspace(0, 1, K))
fig1 = plt.figure(1, figsize=(15, 4))
fig2 = plt.figure(2, figsize=(15, 3))
for center in centers:
ax1 = fig1.add_subplot(1, 2, 1)
ax1.plot(center, color=colors[cluster])
ax2 = fig2.add_subplot(1, K, cluster + 1)
data_cluster = data4clustering_train.iloc[labels == cluster]
ax2.plot(data_cluster.transpose(), alpha=0.1, color="silver")
ax2.plot(center, color=colors[cluster])
ax2.set_xlabel("Hours since admission")
if cluster == 0:
ax2.set_ylabel("Normalized " + variable)
ax2.set_ylim((0, 1))
cluster += 1
data_cluster_mort = (
data["mortality"].loc[data_cluster.index].groupby(["icustay"]).mean()
)
print(
"Cluster "
+ str(cluster)
+ ": "
+ str(data_cluster.shape[0])
+ " observations"
)
mortality_cluster[cluster] = (
sum(data_cluster_mort) / len(data_cluster_mort) * 100
)
d[cluster] = str(cluster)
labels = pd.DataFrame(labels).set_index(data4clustering_train.index)
ax1.legend(d)
ax1.set_xlabel("Hours since ICU admission")
ax1.set_ylabel("Normalized " + variable)
ax1.set_ylim((0, 1))
ax3 = fig1.add_subplot(1, 2, 2)
x, y = zip(*mortality_cluster.items())
ax3.bar(x, y, color=colors)
ax3.set_xlabel("Cluster")
ax3.set_ylabel("Non-survivors (%)")
ax3.set_xticks(np.arange(1, K + 1, step=1))
plt.show()
if args:
return data4clustering, labels, labels_test
else:
return data4clustering, labels
Visual inspection of the best number of clusters for each variable#
In the next example, k-means clustering is performed for glasgow coma scale (GCS), for a varying number of clusters (K). Only the training data is used to identify the clusters. The figures show, by order of appearance:
Fig. 1: cluster centers;
Fig. 2: percentage of non-survivors in each cluster;
Fig. 3+: cluster centers and training data in each cluster.
[33]:
variable = "glasgow coma scale"
clusters = range(2, 6)
ids_clustering = X_train.index.unique()
for K in clusters:
data4clustering, cluster_labels = clustering(variable, ids_clustering, K)
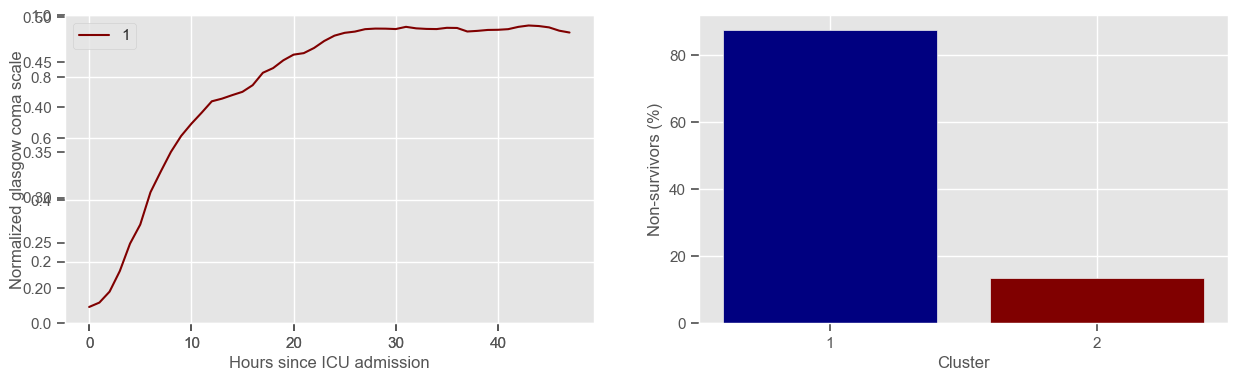
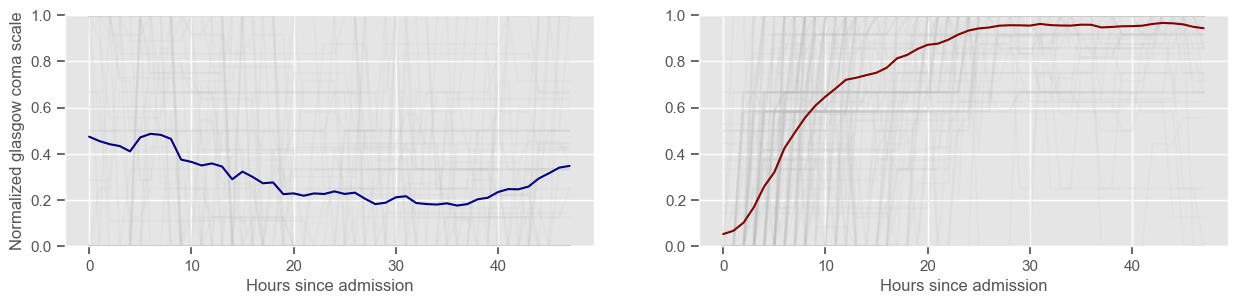
Using 236 ICU stays for creating the clusters
2 clusters
Cluster 1: 72 observations
Cluster 2: 164 observations
Using 236 ICU stays for creating the clusters
3 clusters
Cluster 1: 120 observations
Cluster 2: 64 observations
Cluster 3: 52 observations
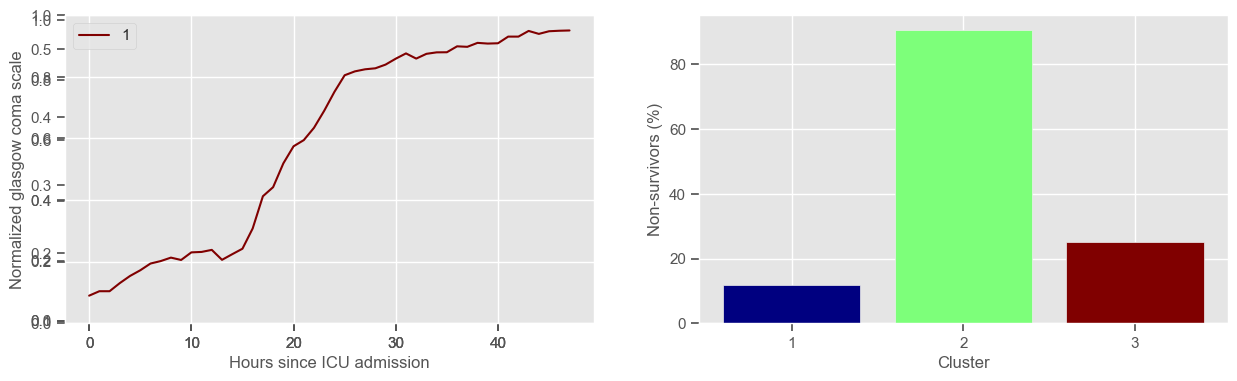
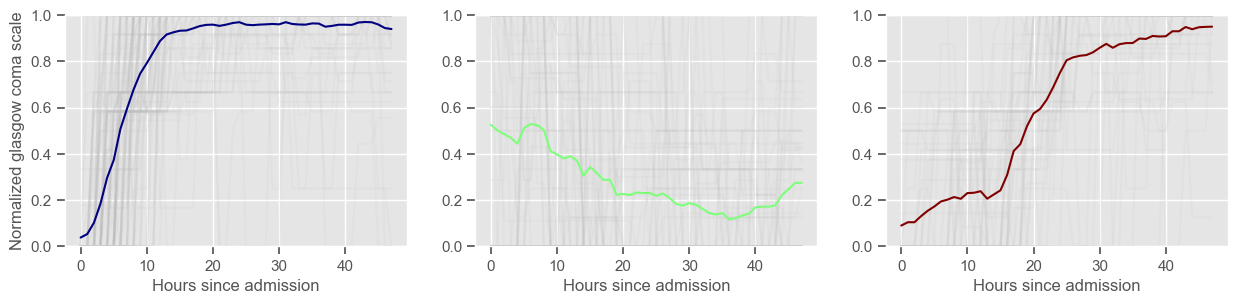
Using 236 ICU stays for creating the clusters
4 clusters
Cluster 1: 37 observations
Cluster 2: 105 observations
Cluster 3: 60 observations
Cluster 4: 34 observations
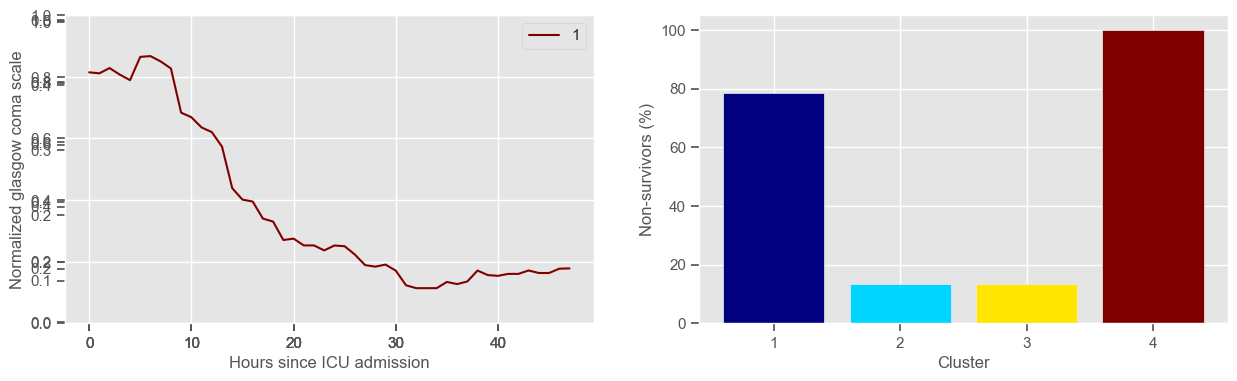
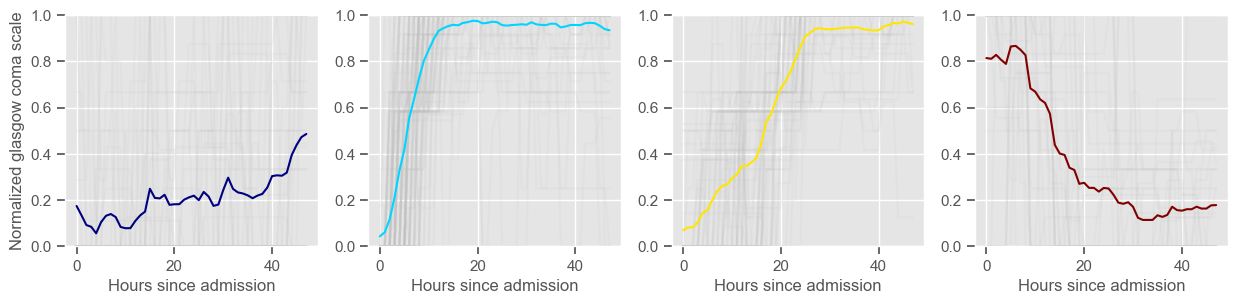
Using 236 ICU stays for creating the clusters
5 clusters
Cluster 1: 26 observations
Cluster 2: 98 observations
Cluster 3: 61 observations
Cluster 4: 29 observations
Cluster 5: 22 observations
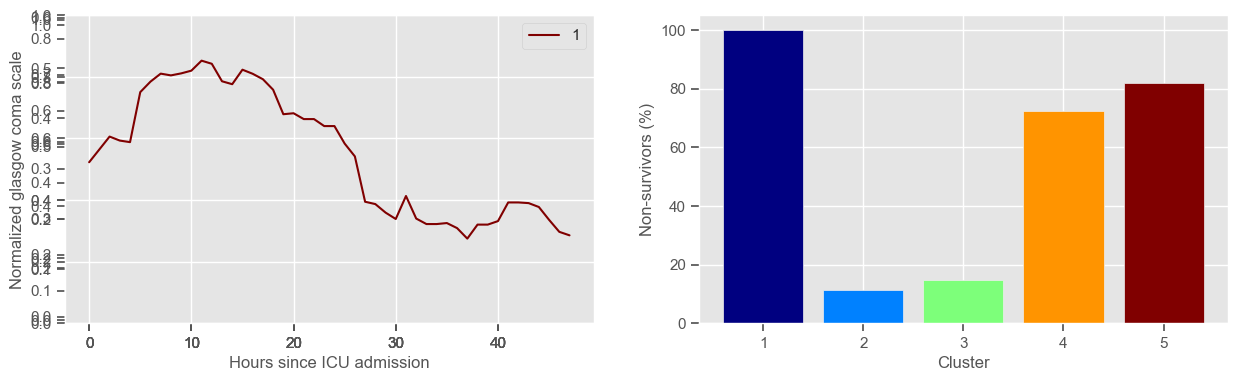
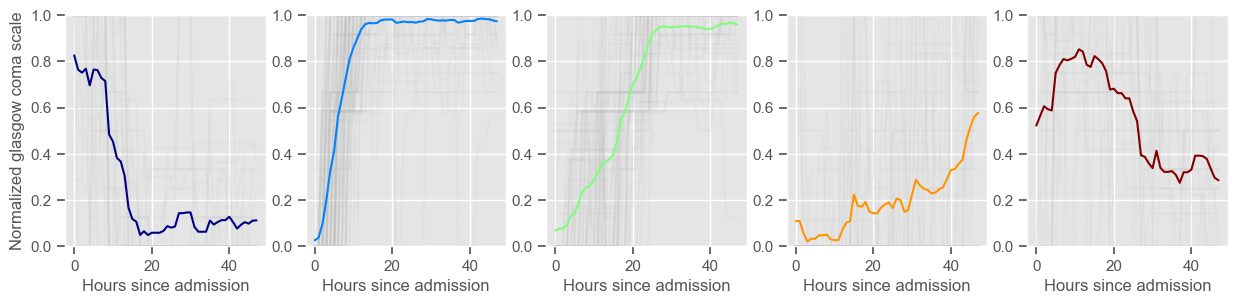
The goal of plotting cluster centers, mortality distribution and data in each cluster is to visually inspect the quality of the clusters. Another option would be to use quantitative methods, typically known as cluster validity indices, that automatically give the “best” number of clusters according to some criteria (e.g., cluster compacteness, cluster separation). Some interesting findings are:
\(K = 2\)
shows two very distinct patterns, similar to what was found by partitioning by mortality;
but, we probably want more stratification;
\(K = 3\)
2 groups where GCS is improving with time;
1 group where GCS is deteriorating;
yes, this is reflected in terms of our ground truth labels, even though we did not provide that information to the clustering. Mortality\(>60\%\) in one cluster vs \(30\%\) and \(28\%\) in the other two clusters;
\(K = 4\)
one more “bad” cluster appears;
\(K = 5\)
Clusters 2 and 4 have similar patterns and similar mortality distribution. GCS is improving with time;
Clusters 3 and 5 have similar mortality distribution. GCS is slowly increasing or decreasing with time;
Cluster 1 is the “worst” cluster. Mortality is close to \(70\%\).
In summary, every \(K\) from 2 to 5 gives an interesting view of the evolution of GCS and its relation with mortality. For the sake of simplicity, this analysis is only shown for GCS. You can investigate on your own the cluster tendency for other variables and decide what is a good number of clusters for all of them. For now, the following K is used for each variable:
[34]:
# create a dictionary of selected K for each variable
Ks = dict(
[
("diastolic BP", 4),
("glasgow coma scale", 4),
("glucose", 5),
("heart rate", 5),
("mean BP", 5),
("oxygen saturation", 3),
("respiratory rate", 5),
("systolic BP", 4),
("temperature", 4),
("pH", 4),
]
)
Training and testing#
In this work, cluster labels are used to add another layer of information to the machine learning models. During the training phase, clustering is performed on the time series from the training set. Cluster centers are created and training observations are assigned to each cluster. During the test phase, test observations are assigned to one of the clusters defined in the training phase. Each observation is assigned to the most similar cluster, i.e., to the cluster whose center is at a smaller distance. These observations are not used to identify clusters centers.
The next example trains/creates and tests/assigns clusters using the ‘clustering’ function previously defined. Cluster labels are stored in ‘cluster_labels_train’ and ‘cluster_labels_test’.
[35]:
id_train = X_train.index.unique()
id_test = X_test.index.unique()
cluster_labels_train = pd.DataFrame()
cluster_labels_test = pd.DataFrame()
for feature in variables:
print(feature)
K = Ks[feature]
data4clustering, labels_train, labels_test = clustering(
feature, id_train, K, id_test
)
labels_test.columns = ["CL " + feature]
labels_train.columns = ["CL " + feature]
cluster_labels_train = pd.concat(
[cluster_labels_train, labels_train], axis=1
).dropna(axis=0)
cluster_labels_test = pd.concat([cluster_labels_test, labels_test], axis=1).dropna(
axis=0
)
for col in cluster_labels_train:
cluster_labels_train[col] = cluster_labels_train[col].astype("category")
for col in cluster_labels_test:
cluster_labels_test[col] = cluster_labels_test[col].astype("category")
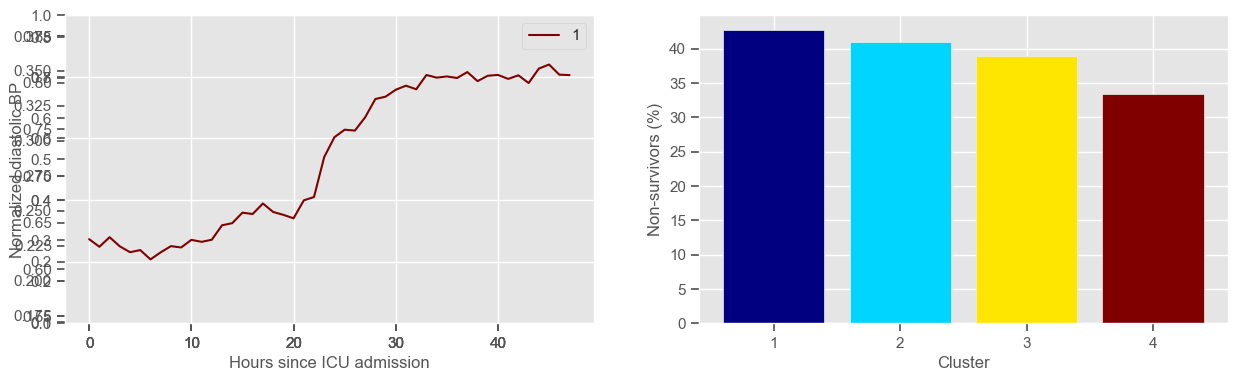
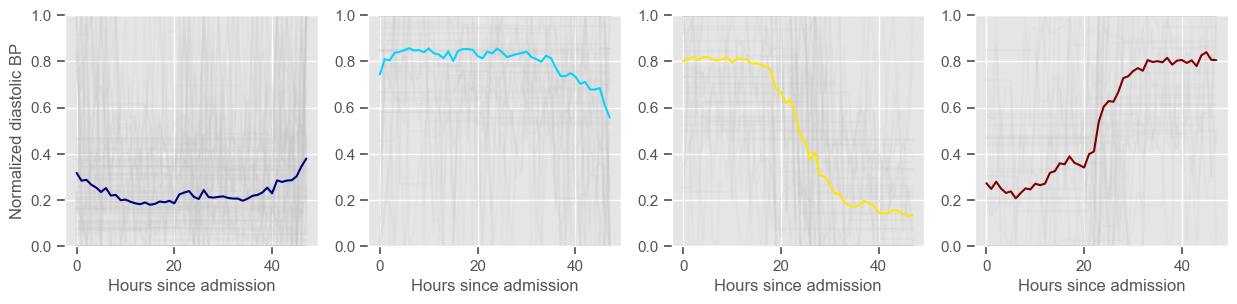
diastolic BP
Using 265 ICU stays for creating the clusters
Using 482 ICU stays for cluster assignment
4 clusters
Cluster 1: 103 observations
Cluster 2: 61 observations
Cluster 3: 59 observations
Cluster 4: 42 observations
glasgow coma scale
Using 236 ICU stays for creating the clusters
Using 461 ICU stays for cluster assignment
4 clusters
Cluster 1: 37 observations
Cluster 2: 105 observations
Cluster 3: 60 observations
Cluster 4: 34 observations
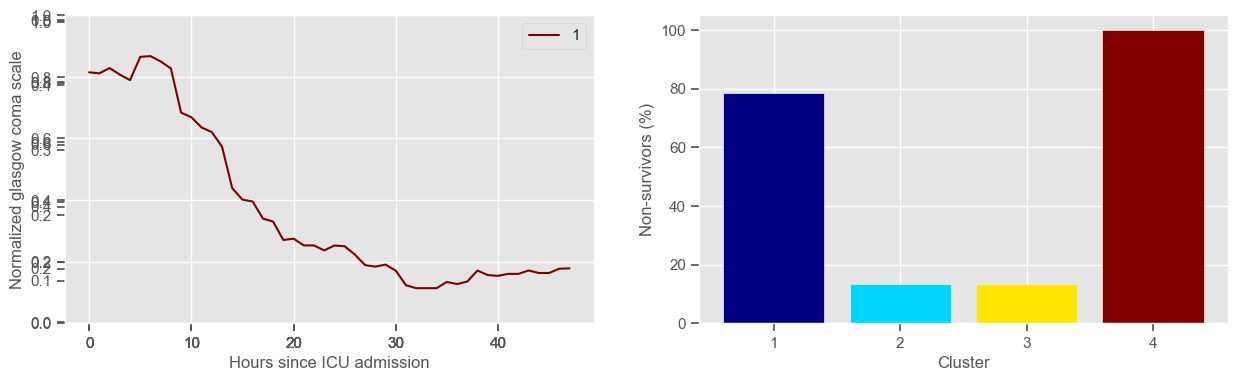
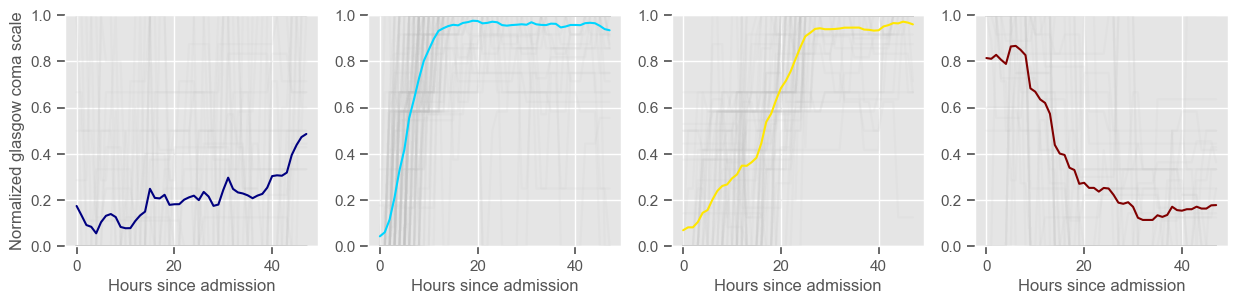
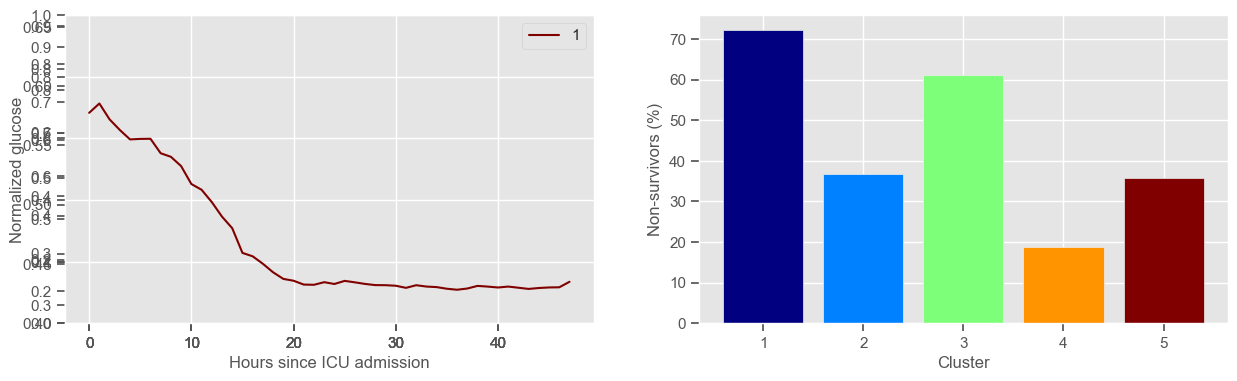
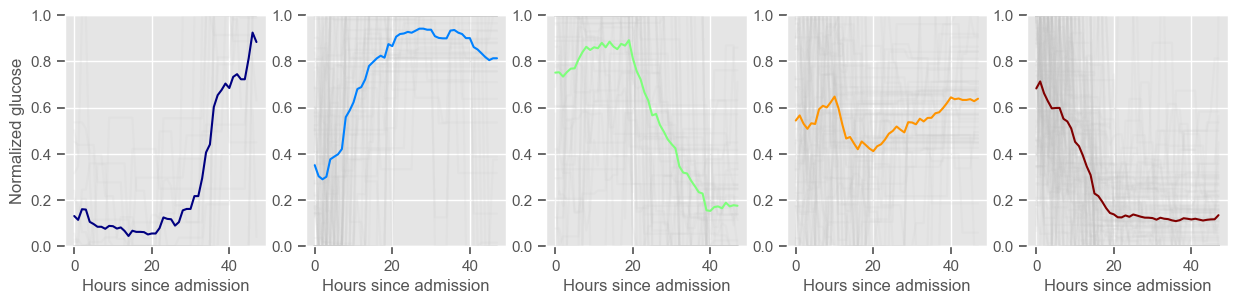
glucose
Using 267 ICU stays for creating the clusters
Using 482 ICU stays for cluster assignment
5 clusters
Cluster 1: 18 observations
Cluster 2: 60 observations
Cluster 3: 49 observations
Cluster 4: 48 observations
Cluster 5: 92 observations
heart rate
Using 266 ICU stays for creating the clusters
Using 482 ICU stays for cluster assignment
5 clusters
Cluster 1: 60 observations
Cluster 2: 40 observations
Cluster 3: 53 observations
Cluster 4: 60 observations
Cluster 5: 53 observations
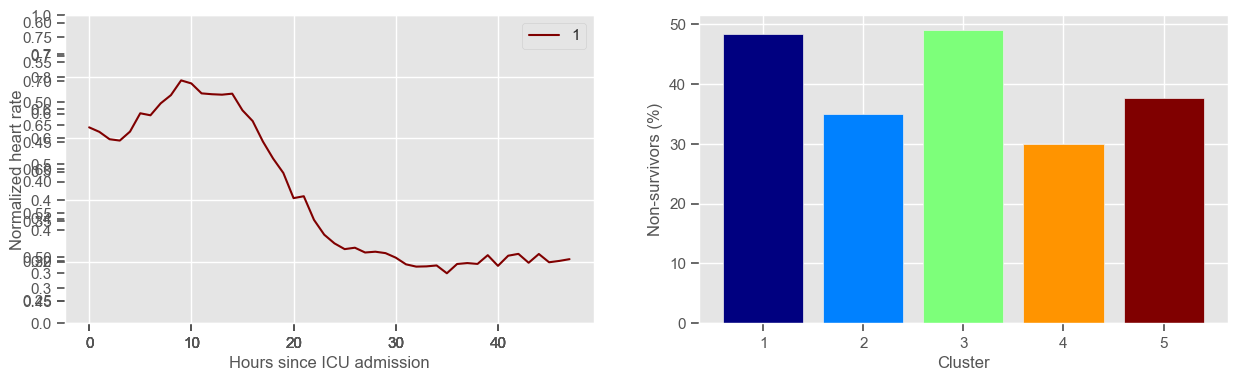
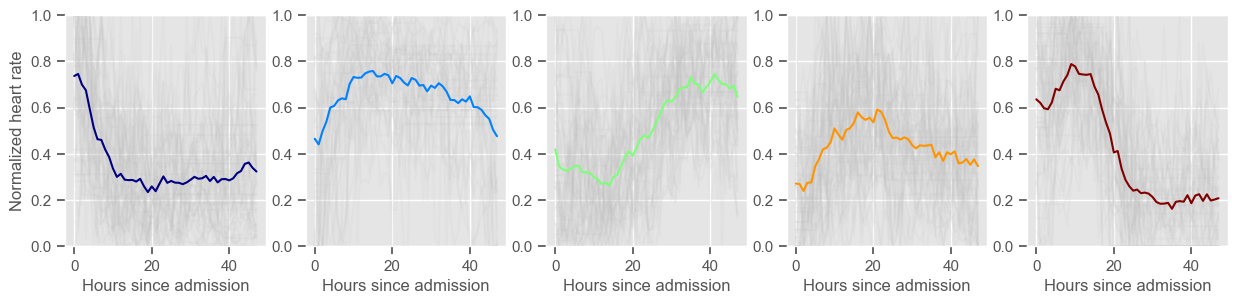
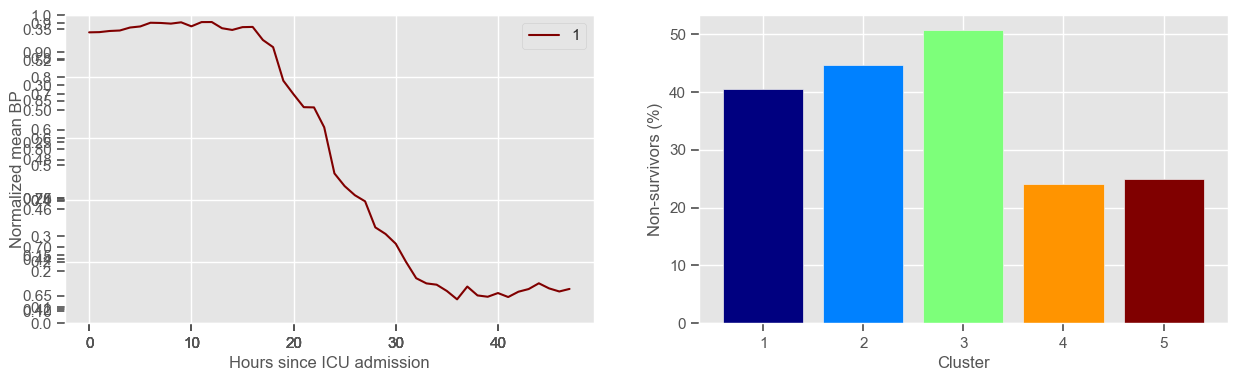
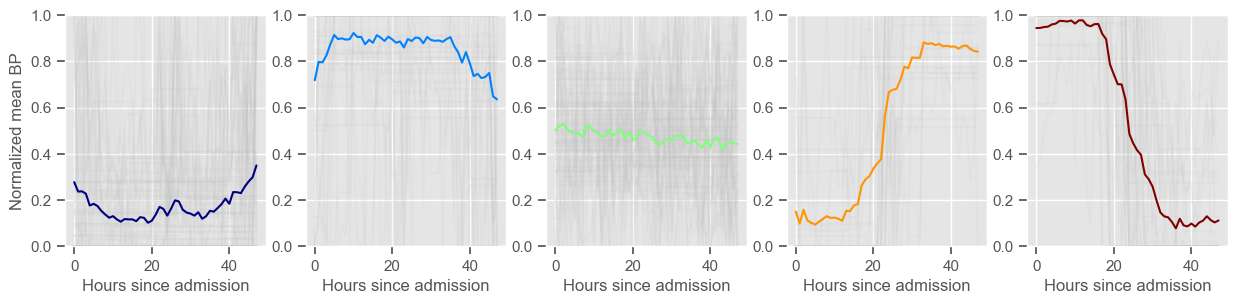
mean BP
Using 266 ICU stays for creating the clusters
Using 481 ICU stays for cluster assignment
5 clusters
Cluster 1: 79 observations
Cluster 2: 47 observations
Cluster 3: 71 observations
Cluster 4: 29 observations
Cluster 5: 40 observations
oxygen saturation
Using 267 ICU stays for creating the clusters
Using 481 ICU stays for cluster assignment
3 clusters
Cluster 1: 47 observations
Cluster 2: 98 observations
Cluster 3: 122 observations
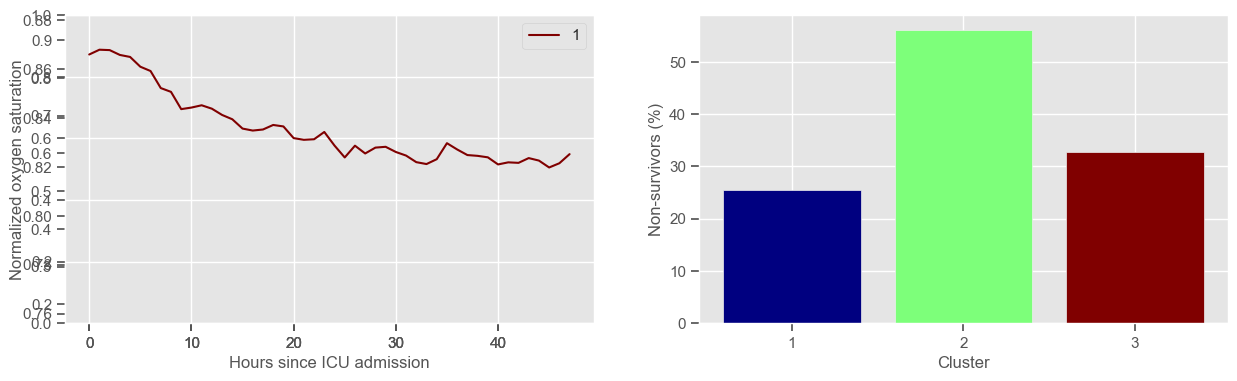
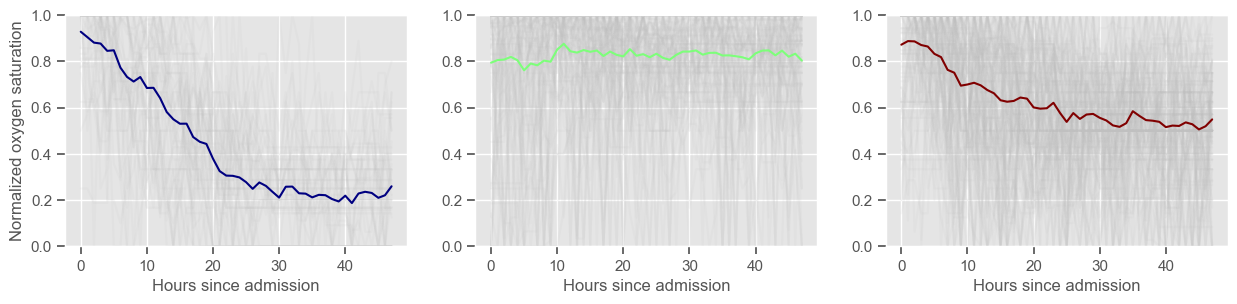
respiratory rate
Using 267 ICU stays for creating the clusters
Using 482 ICU stays for cluster assignment
5 clusters
Cluster 1: 42 observations
Cluster 2: 57 observations
Cluster 3: 43 observations
Cluster 4: 79 observations
Cluster 5: 46 observations
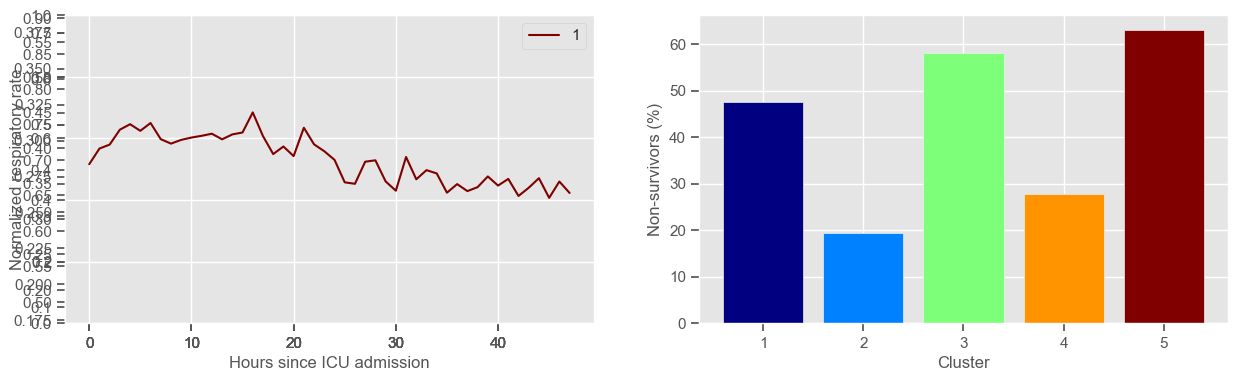
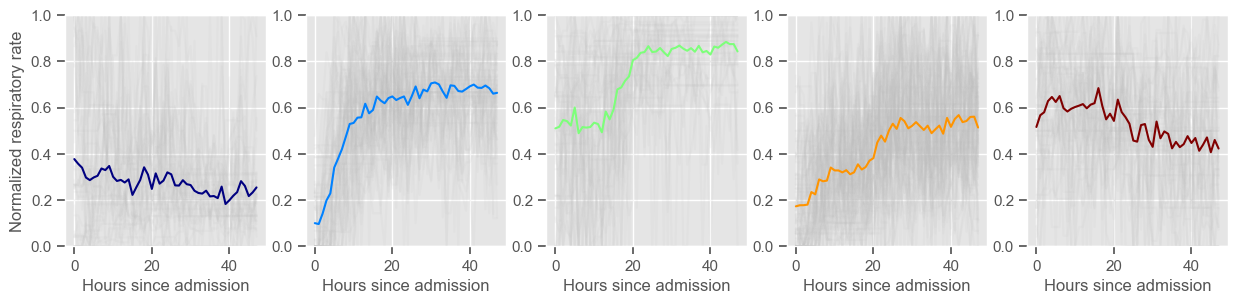
systolic BP
Using 266 ICU stays for creating the clusters
Using 480 ICU stays for cluster assignment
4 clusters
Cluster 1: 61 observations
Cluster 2: 85 observations
Cluster 3: 60 observations
Cluster 4: 60 observations
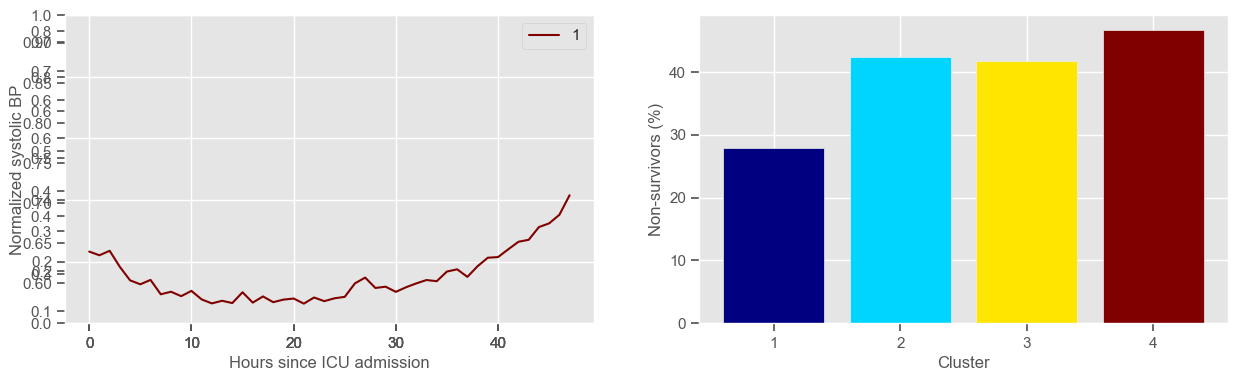
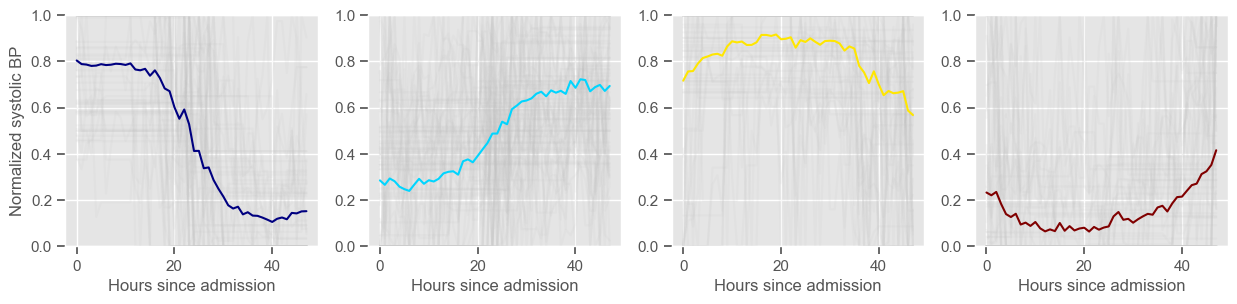
temperature
Using 267 ICU stays for creating the clusters
Using 481 ICU stays for cluster assignment
4 clusters
Cluster 1: 68 observations
Cluster 2: 40 observations
Cluster 3: 93 observations
Cluster 4: 66 observations
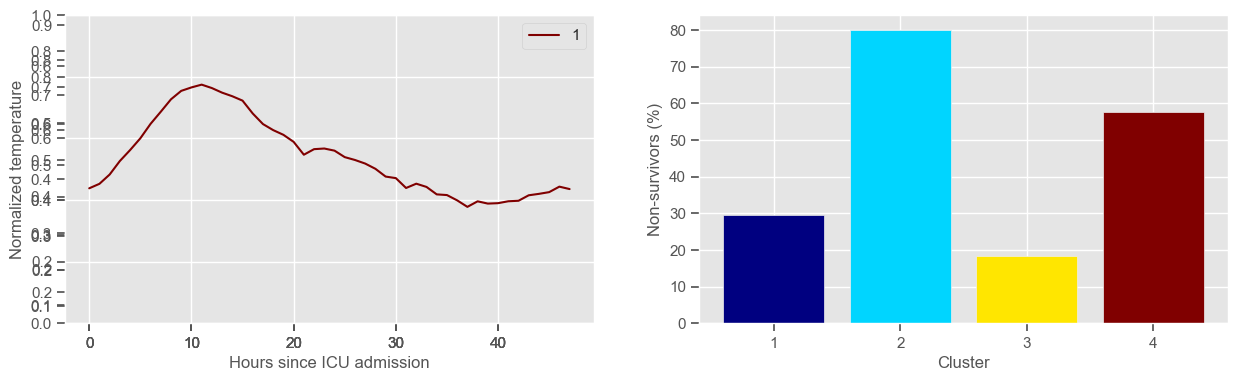
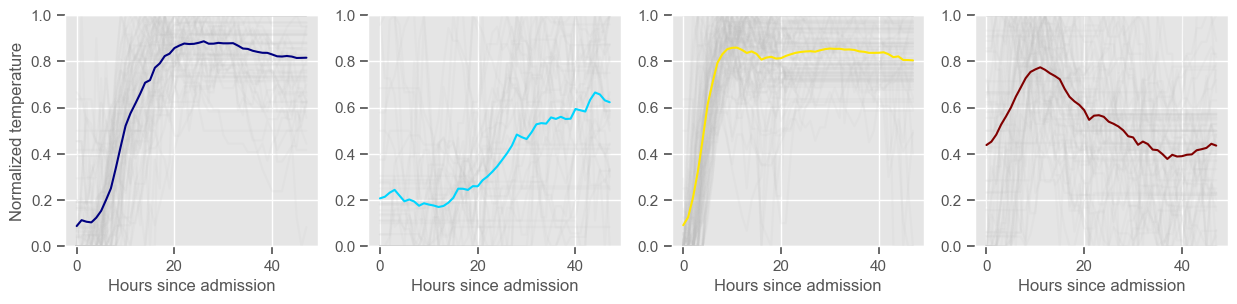
pH
Using 267 ICU stays for creating the clusters
Using 482 ICU stays for cluster assignment
4 clusters
Cluster 1: 58 observations
Cluster 2: 51 observations
Cluster 3: 77 observations
Cluster 4: 81 observations
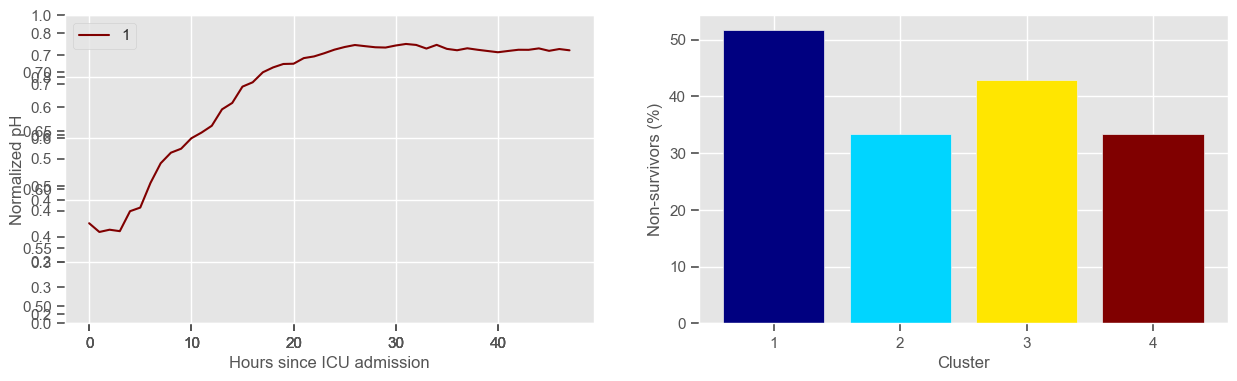
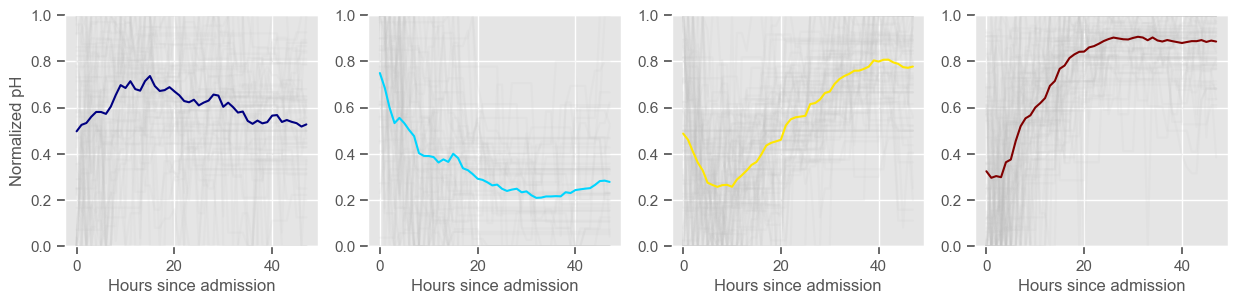
Clustering allowed us to stratify patients according to their physiological evolution during the first 48 hours in the ICU. Since cluster centers reflect the cluster tendency, it is possible to investigate the relation between distinct physiological patterns and mortality, and ascertain if the relation is expected.
For example, cluster 4 and cluster 5 in glucose are more or less symmetric: in cluster 4, patients start with low glucose, which increases over time until it decreases again; in cluster 5, patients start with high glucose, which decreases over time until it increases again. In the first case, mortality is approximately \(45\%\) and in the second case it is approximately \(30\%\). Although this is obviously not enough to predict mortality, it highlights a possible relationship between the evolution of glucose and mortality. If a certain patient has a pattern of glucose similar to cluster 4, there may be more reason for concern than if he/she expresses the pattern in cluster 5.
By now, some particularities of the type of normalization performed can be noted:
It hinders interpretability;
It allows the algorithm to group together patients that did not present significant changes in their physiological state through time, regardless of the absolute value of the observations.
We have seen how clustering can be used to stratify patients, but not how it can be used to predict outcomes. Predictive models that use the information provided by clustering are investigated next. Models are created for the extracted features together with cluster information. This idea is represented in the next figure.
Normalization#
Normalization, or scaling, is used to ensure that all features lie between a given minimum and maximum value, often between zero and one. The maximum and minimum values of each feature should be determined during the training phase and the same values should be applied during the test phase.
The next example is used to normalize the features extracted from the time series.
[36]:
X_train_min = X_train.min()
X_train_max = X_train.max()
X_train_norm = (X_train - X_train_min) / (X_train_max - X_train_min)
X_test_norm = (X_test - X_train_min) / (X_train_max - X_train_min)
Normalization is useful when solving for example least squares or functions involving the calculation of distances. Normalization does not impact the performance of a decision tree. Contrary to what was done in clustering, the data is normalized for the entire dataset at once, and not for each patient individually.
The next example uses the ‘preprocessing’ package from ‘sklearn’ which performs exactly the same:
[37]:
from sklearn import preprocessing
min_max_scaler = preprocessing.MinMaxScaler()
X_train_norm_skl = pd.DataFrame(min_max_scaler.fit_transform(X_train))
# the same normalization operations will be applied to be consistent with the transformation performed on the train data.
X_test_norm_skl = pd.DataFrame(min_max_scaler.transform(X_test))
Concatenate predicted clustering labels with extracted features#
The ‘get_dummies’ function from ‘pandas’ will be used to get dummy variables for the cluster labels obtained through k-means. The idea is to use binary cluster labels, i.e., features indicating “yes/no belongs to cluster k”, as input to the models. This will give an extra level of information regarding the clinical temporal evolution of the patient in a multidimensional space.
You can add a ‘drop_first’ parameter to the ‘get_dummies’ function to indicate if you want to exclude one category, i.e., whether to get k-1 dummies out of k categorical levels by removing the first level. Because we will perform feature selection, this option does not need to be selected.
[38]:
# drop_first : bool, default False
# use drop_first=True to exclude one of the categories
X_train_clust = pd.get_dummies(cluster_labels_train, prefix_sep=" ")
y_train_clust = pd.DataFrame(
data_transf_inv.loc[cluster_labels_train.index]["mortality"]
)
X_test_clust = pd.get_dummies(cluster_labels_test, prefix_sep=" ")
y_test_clust = pd.DataFrame(data_transf_inv.loc[cluster_labels_test.index]["mortality"])
X_train = pd.concat([X_train_norm, X_train_clust], axis=1).dropna(axis=0)
y_train = y_train.loc[X_train.index]
X_test = pd.concat([X_test_norm, X_test_clust], axis=1).dropna(axis=0)
y_test = y_test.loc[X_test.index]
The next example prints the number of observations in the training and test sets, total number of features and a snapshot of the data.
[39]:
print("Number of observations in training set: " + str(X_train.shape[0]))
print("Number of observations in test set: " + str(X_test.shape[0]))
print("Number of features: " + str(X_train.shape[1]))
display.display(X_train.head())
Number of observations in training set: 233
Number of observations in test set: 458
Number of features: 85
| min diastolic BP | min glasgow coma scale | min glucose | min heart rate | min mean BP | min oxygen saturation | min respiratory rate | min systolic BP | min temperature | min pH | ... | CL systolic BP 2.0 | CL systolic BP 3.0 | CL temperature 0.0 | CL temperature 1.0 | CL temperature 2.0 | CL temperature 3.0 | CL pH 0 | CL pH 1 | CL pH 2 | CL pH 3 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| icustay | |||||||||||||||||||||
| 239323 | 0.533333 | 0.000000 | 0.119298 | 0.597826 | 0.538983 | 0.898990 | 0.418182 | 0.563694 | 0.677725 | 0.663266 | ... | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 |
| 265618 | 0.653333 | 0.666667 | 0.214035 | 0.663043 | 0.711865 | 0.868687 | 0.000000 | 0.649682 | 0.734597 | 0.714286 | ... | 0.0 | 1.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 |
| 264276 | 0.000000 | 0.000000 | 0.119298 | 0.315217 | 0.549153 | 0.868687 | 0.327273 | 0.000000 | 0.838862 | 0.551020 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 1.0 | 0.0 | 0.0 | 0.0 |
| 228038 | 0.453333 | 0.583333 | 0.070175 | 0.510870 | 0.542373 | 0.934343 | 0.363636 | 0.585987 | 0.701422 | 0.653061 | ... | 1.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 |
| 282751 | 0.846667 | 0.000000 | 0.140351 | 0.538043 | 0.742373 | 0.944444 | 0.400000 | 0.624204 | 0.654029 | 0.816326 | ... | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 |
5 rows × 85 columns
The dataset is now composed of a mixture of summary statistics obtained through simple operations and clustering. Cluster labels are categorized as ‘CL’. For example, ‘CL 0.0’ corresponds to cluster 1, ‘CL 1.0’ to cluster 2 and so on.
Machine learning#
The next section focuses on building mortality prediction models/classifiers using common algorithms and the ‘sklearn’ library, in particular k-Nearest neighbors, logistic regression, decision trees and random forest. Before starting, it is important to define what performance measures should be used to evaluate the performance of different classifiers.
Definition of performance measures#
Having a single-number evaluation metric is useful for comparing the performance of different models. Accuracy can be misleading when classes are imbalanced. Sensitivity (also called recall or true positive rate) is a useful measure that indicates the percentage of non-survivors who are correctly identified as such. In the context of our problem, having a high sensitivity is very important, since it tells us the algorithm is able to correctly identify the most critical cases. However, optimizing for sensitivity alone may lead to the presence of many false alarms (false positives). Therefore, it is important to also have in mind specificity, which tells us the the percentage of survivors who are correctly identified as such. Sensitivity and specificity are given by:
Sensitivity = \(\frac{TP}{TP + FN}\)
Specificity = \(\frac{TN}{TN + FP}\)
One way of combining sensitivity and specificity in one measure is using the area under the receiver–operator characteristics (ROC) curve (AUC), which is a graphical plot that illustrates the performance of a binary classifier as its discrimination threshold is varied.
The following function shows how to calculate the number of true positives, true negatives, false positives, false negatives, accuracy, sensitivity, specificity and AUC using the ‘metrics’ and ‘confusion_matrix’ packages from ‘sklearn’; how to plot the ROC curve and how to choose a threshold in order to convert a continuous-value output into a binary classification.
[40]:
from sklearn import metrics
from sklearn.metrics import confusion_matrix
def performance(y, y_pred, print_=1, *args):
"""Calculate performance measures for a given ground truth classification y and predicted
probabilities y_pred. If *args is provided a predifined threshold is used to calculate the performance.
If not, the threshold giving the best mean sensitivity and specificity is selected. The AUC is calculated
for a range of thresholds using the metrics package from sklearn."""
# xx and yy values for ROC curve
fpr, tpr, thresholds = metrics.roc_curve(y, y_pred, pos_label=1)
# area under the ROC curve
AUC = metrics.auc(fpr, tpr)
if args:
threshold = args[0]
else:
# we will choose the threshold that gives the best balance between sensitivity and specificity
difference = abs((1 - fpr) - tpr)
threshold = thresholds[difference.argmin()]
# transform the predicted probability into a binary classification
y_pred[y_pred >= threshold] = 1
y_pred[y_pred < threshold] = 0
tn, fp, fn, tp = confusion_matrix(y, y_pred).ravel()
sensitivity = tp / (tp + fn)
specificity = tn / (tn + fp)
accuracy = (tp + tn) / (tp + tn + fp + fn)
# print the performance and plot the ROC curve
if print_ == 1:
print("Threshold: " + str(round(threshold, 2)))
print("TP: " + str(tp))
print("TN: " + str(tn))
print("FP: " + str(fp))
print("FN: " + str(fn))
print("Accuracy: " + str(round(accuracy, 2)))
print("Sensitivity: " + str(round(sensitivity, 2)))
print("Specificity: " + str(round(specificity, 2)))
print("AUC: " + str(round(AUC, 2)))
plt.figure(figsize=(4, 3))
plt.scatter(x=fpr, y=tpr, label=None)
plt.plot(fpr, tpr, label="Classifier", zorder=1)
plt.plot([0, 1], [0, 1], "k--", label="Random classifier")
plt.scatter(
x=1 - specificity,
y=sensitivity,
c="black",
label="Operating point",
zorder=2,
)
plt.legend()
plt.xlabel("1 - specificity")
plt.ylabel("sensitivity")
plt.show()
return threshold, AUC, sensitivity, specificity
Logistic regression#
When starting a machine learning project it is always a good approach to start with a very simple model since it will give a sense of how challenging the question is. Logistic regression (LR) is considered a simple model especially because it is easy to understand the math behind it, which makes it also easy to interpret the model parameters and results, and it takes little time computing compared to other ML models.
Feature selection#
In order to reduce multicollinearity, and because we are interested in increasing the interpretability and simplicity of the model, feature selection is highly recommended. Multicollinearity exists when two or more of the predictors in a regression model are moderately or highly correlated. The problem with multicollinearity is that it makes some variables statistically insignificant when they are not necessarily so, because the estimated coefficient of one variable depends on which collinear variables are included in the model. High multicollinearity increases the variance of the regression coefficients, making them unstable, but a little bit of multicollinearity is not necessarily a problem. As you will see, the algorithm used for feature selection does not directly addresses multicollinearity, but indirectly helps reducing it by reducing the size of the feature space.
Sequential forward selection / forward stepwise selection#
The sequential forward selection (SFS) algorithm is an iterative process where the subset of features that best predicts the output is obtained by sequentially selecting features until there is no improvement in prediction. The criterion used to select features and to determine when to stop is chosen based on the objectives of the problem. In this work, the criterion maximization of average sensitivity and specificity will be used.
In the first iteration, models with one feature are created (univariable analysis). The model giving the higher average sensitivity and specificity in the validation set is selected. In the second iteration, the remaining features are evaluated again one at a time, together with the feature selected in the previous iteration. This process continues until there is no significant improvement in performance.
In order to evaluate different feature sets, the training data is divided into two sets, one for training and another for validation. This can be easily achieved using the ‘train_test_split’ as before:
[41]:
val_size = 0.4
X_train_SFS, X_val_SFS, y_train_SFS, y_val_SFS = train_test_split(
X_train, y_train, test_size=val_size, random_state=10
)
Since there is no SFS implementation in python, the algorithm is implemented from scratch in the next example. The ‘linear model’ package from ‘sklearn’ is used to implement LR and a minimum improvement of 0.0005 is used in order to visualize the algorithm for a few iterations. The figure shows the performance associated with each feature at each iteration of the algorithm. Different iterations have different colors and at each iteration one feature is selected and marked with a red dot. Note that this operation will take some time to compute. You can decrease the ‘min_improv’ to visualize the algorithm for fewer iterations or increase it to allow more features to be added to the final set. You can also remove the lines of code for plotting the performance at each run, in order to reduce the time of computation.
[42]:
from sklearn.linear_model import LogisticRegression
from matplotlib import cm
# min_improv = 0.1
min_improv = 0.0005
to_test_features = X_train_SFS.columns
selected_features_sfs = []
test_set = []
results_selected = []
previous_perf = 0
gain = 1
it = 0
# create figure
plt.figure(num=None, figsize=(15, 6))
plt.xticks(rotation="vertical", horizontalalignment="right")
plt.ylabel("Average sensitivity specificity")
colors = cm.tab20(np.linspace(0, 1, 180))
# just make sure you select an interval that gives you enough colors
colors = colors[::10]
# perform SFS while there is a gain in performance
while gain >= min_improv:
frames = []
color = colors[it]
it += 1
# add one feature at a time to the previously selected feature set.
for col in to_test_features:
test_set = selected_features_sfs.copy()
test_set.append(col)
# train model
model = LogisticRegression(random_state=1)
model.fit(X_train_SFS[test_set], y_train_SFS.values.ravel())
# test performance
y_pred_prob = model.predict_proba(X_val_SFS[test_set])
_, AUC, sens, spec = performance(
y_val_SFS, np.delete(y_pred_prob, 0, 1), print_=0
)
# save the results
frames.append([test_set, (sens + spec) / 2])
# plot the performance
plt.scatter(x=col, y=(sens + spec) / 2, c=color)
display.display(plt.gcf())
display.clear_output(wait=True)
time.sleep(0.001)
# select best feature combination
results = pd.DataFrame(frames, columns=("Feature", "Performance"))
id_max = results.loc[results["Performance"].idxmax()]
gain = id_max["Performance"] - previous_perf
# plot selected feature combination in red
plt.scatter(x=id_max["Feature"][-1], y=id_max["Performance"], c="red", s=150)
# test if selected feature combination improves the performance above predefined 'min_improv'
if gain > min_improv:
previous_perf = id_max["Performance"]
to_test_features = to_test_features.drop(id_max["Feature"][-1])
selected_features_sfs.append(id_max["Feature"][-1])
results_selected.append(id_max)
# if not, do not had the last feature to the feature set. Exit the loop
results_selected = pd.DataFrame(results_selected)
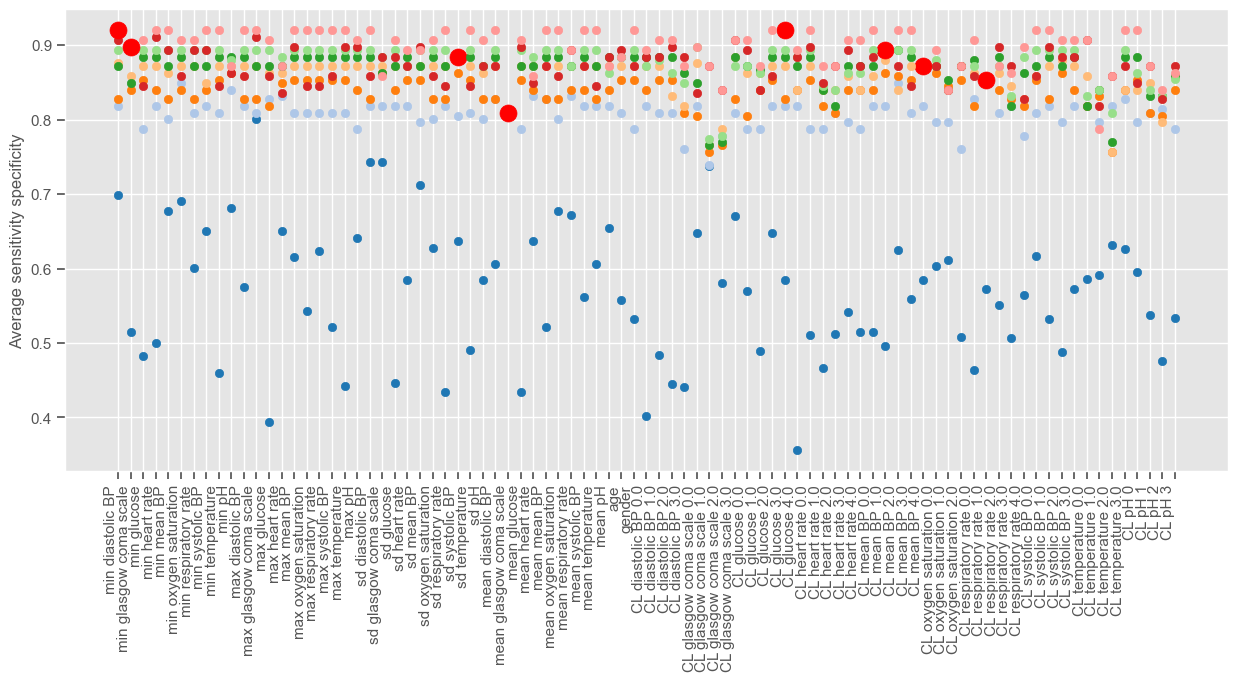
Iteration 1 (blue dots associated with lower performance) corresponds to a univariable analysis. At this stage, maximum GCS is selected since it gives the higher average sensitivity specificity. Iteration 2 corresponds to a multivariable analysis (GCS plus every other independent variable). There is a big jump from iteration 1 to iteration 2, as expected, and small improvements thereafter until the performance reaches a plateau. We can plot the performance obtained at each iteration:
[43]:
plt.figure(num=None, figsize=(10, 4))
plt.scatter(
x=range(1, results_selected.shape[0] + 1, 1),
y=results_selected["Performance"],
c="red",
s=150,
)
plt.xticks(
range(1, results_selected.shape[0] + 1, 1),
results_selected["Feature"].iloc[-1],
rotation="vertical",
)
plt.ylabel("AUC")
plt.show()
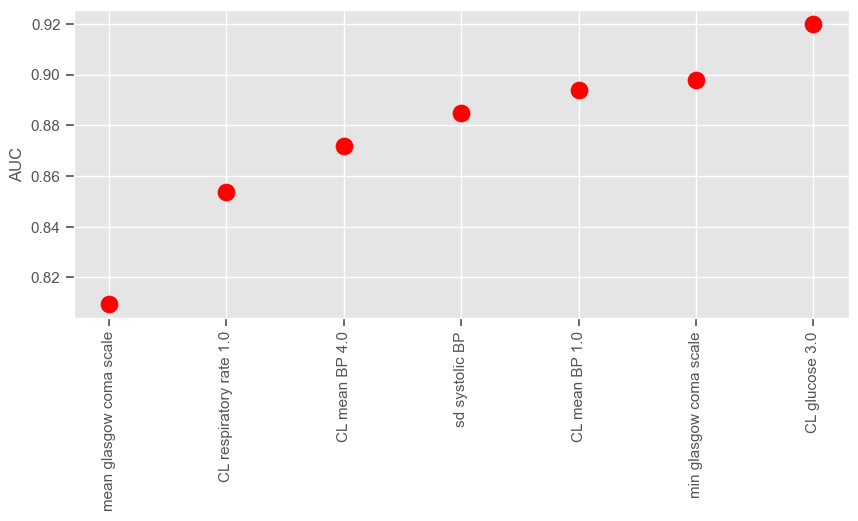
According to SFS, important features that help predict the outcome are:
Maximum GCS, decrease in GCS during the first hours in the ICU associated with high mortality (cluster 3);
Age;
Maximum heart rate;
Minimum and maximum pH;
Mean respiratory rate;
Small increase in diastolic BP during the first 24 hours (cluster 2);
Variation in systolic BP;
Maximum and variation in glucose.
In the exercises you will be advised to investigate how these conclusions change when a different data partitioning is used for training and testing. You can do this by changing the random seed.
Remember that for large number of features (85 in our case) we cannot compute the best subset sequence. This would mean testing all combinations of 85 features, 1 to 85 at a time. It is hard enough to calculate the number of combinations, let alone train models for every one of them. That is why everyone uses greedy algorithms that lead to sub-optimal solutions. Even k-means, which is very fast (one of the fastest clustering algorithms available), falls in local minima.
Recursive Feature Elimination (RFE)#
Recursive feature elimination is similar to forward stepwise selection, only in this case features are recursively eliminated (as opposed to being recursively added) from the feature set. It can be implemented using the ‘RFE’ function from ‘sklearn’. In ‘sklearn’ documentation website you will find:
“Given an external estimator that assigns weights to features (e.g., the coefficients of a linear model), the goal of recursive feature elimination (RFE) is to select features by recursively considering smaller and smaller sets of features. First, the estimator is trained on the initial set of features and the importance of each feature is obtained either through a ‘coef_’ attribute or through a ‘feature_importances_’ attribute. Then, the least important features are pruned from current set of features. That procedure is recursively repeated on the pruned set until the desired number of features to select is eventually reached.”
The disadvantage of using the ‘sklearn’ implementation of RFE is that you are limited to using ‘coef_’ or ‘feature_importances_’ attributes to recursively exclude features. Since LR retrieves a ‘coef_’ attribute, this means RFE will recursively eliminate features that have low coefficients, and not features giving the lower average sensitivity specificity as we would like to if we were to follow the example previously given with SFS.
Similarly to SFS, a stopping criteria must also be defined. In this case, the stopping criteria is the number of features. If the number of features is not given (‘n_features_to_select’ = None), half of the features are automatically selected. For illustrative purposes, the next example shows how to use RFE to select 13 features:
[44]:
from sklearn.feature_selection import RFE
n_features_to_select = 13
logreg = LogisticRegression(random_state=1)
rfe = RFE(estimator=logreg, n_features_to_select=n_features_to_select)
rfe = rfe.fit(X_train, y_train.values.ravel())
The attribure ‘support_’ gives a mask of selected features:
[45]:
selected_features_rfe = X_train.columns[rfe.support_]
print("Number of features selected: " + str(len(selected_features_rfe)))
print()
print("Selected features:")
display.display(selected_features_rfe)
Number of features selected: 13
Selected features:
Index(['min diastolic BP', 'min heart rate', 'min respiratory rate', 'min pH',
'sd glasgow coma scale', 'mean glasgow coma scale', 'mean pH',
'CL glasgow coma scale 1.0', 'CL glasgow coma scale 2.0',
'CL glasgow coma scale 3.0', 'CL glucose 0.0', 'CL mean BP 4.0',
'CL temperature 1.0'],
dtype='object')
The attribute ‘ranking_’ gives the feature ranking. Features are ranked according to when they were eliminated and selected features are assigned rank 1:
[46]:
rfe.ranking_
[46]:
array([ 1, 6, 56, 1, 45, 9, 1, 14, 66, 1, 32, 2, 38, 35, 3, 22, 60,
57, 18, 13, 63, 1, 34, 40, 58, 20, 36, 25, 30, 27, 21, 1, 72, 16,
64, 5, 10, 71, 12, 1, 44, 31, 67, 49, 59, 29, 39, 1, 1, 1, 1,
11, 41, 7, 73, 52, 24, 53, 54, 23, 33, 8, 28, 69, 1, 51, 4, 50,
61, 26, 65, 42, 43, 37, 62, 48, 55, 19, 1, 17, 70, 46, 68, 47, 15])
For example, the last feature to be excluded by RFE is:
[47]:
X_train.columns[rfe.ranking_.argmax()]
[47]:
'CL glucose 4.0'
However, this does not mean that this particular cluster tendency of glucose is not important; such conclusion cannot be drawn due to the presence of other features that are highly correlated with this one.
SFS and RFE selected the following features in common:
[48]:
list(set(selected_features_rfe) & set(selected_features_sfs))
[48]:
['mean glasgow coma scale', 'CL mean BP 4.0']
Model testing#
Feature selection has been performed using training and validation sets. In the next steps, the performance is evaluated using an independent test set not used to select features. First, a LR model is fitted to the training data on the feature set selected by SFS:
[49]:
model = LogisticRegression(random_state=1)
model.fit(X_train[selected_features_sfs], y_train.values.ravel())
[49]:
LogisticRegression(random_state=1)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
LogisticRegression(random_state=1)
Next, a general function called ‘model_evaluation’ is created in order to:
give probability estimates for unseen data. This is achieved using the ‘predict_proba’ function;
evaluate model performance using both training and test sets.
[50]:
def model_evaluation(model, X_train, y_train, X_test, y_test, print_):
# tune - parameter estimation
print("TRAINING SET")
y_pred_prob_train = model.predict_proba(X_train)
threshold, AUC_train, sens_train, spec_train = performance(
y_train, np.delete(y_pred_prob_train, 0, 1), print_
)
# test
print("TEST SET")
y_pred_prob_test = model.predict_proba(X_test)
_, AUC_test, sens_test, spec_test = performance(
y_test, np.delete(y_pred_prob_test, 0, 1), print_, threshold
)
# save the results
results_train = pd.DataFrame(
data=[[threshold, AUC_train, sens_train, spec_train, X_train.shape[1]]],
columns=["Threshold", "AUC", "Sensitivity", "Specificity", "# features"],
)
results_test = pd.DataFrame(
data=[[threshold, AUC_test, sens_test, spec_test, X_train.shape[1]]],
columns=["Threshold", "AUC", "Sensitivity", "Specificity", "# features"],
)
return results_train, results_test, y_pred_prob_train, y_pred_prob_test
We can call the function to evaluate the previous model on test data:
[51]:
results_train, results_test, y_pred_prob_train, y_pred_prob_test = model_evaluation(
model,
X_train[selected_features_sfs],
y_train,
X_test[selected_features_sfs],
y_test,
print_=1,
)
TRAINING SET
Threshold: 0.36
TP: 73
TN: 129
FP: 20
FN: 11
Accuracy: 0.87
Sensitivity: 0.87
Specificity: 0.87
AUC: 0.91
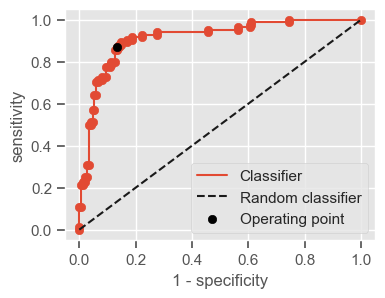
TEST SET
Threshold: 0.36
TP: 20
TN: 376
FP: 58
FN: 4
Accuracy: 0.86
Sensitivity: 0.83
Specificity: 0.87
AUC: 0.88
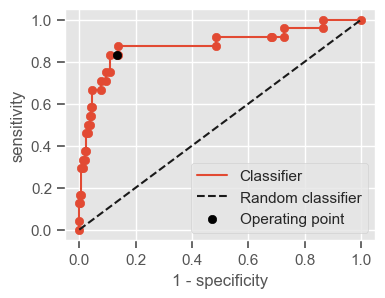
Results are assigned to a DataFrame for future reference, with the label ‘LR SFS’:
[52]:
all_results_train = pd.DataFrame()
all_results_test = pd.DataFrame()
all_results_train = all_results_train.append(
results_train.rename(index={results_train.index[-1]: "LR SFS"})
)
all_results_test = all_results_test.append(
results_test.rename(index={results_test.index[-1]: "LR SFS"})
)
The coefficients of the model can be visualized using the ‘coef_’ attribute. The next function takes a LR model and column names and plots the model coefficients in ascending order:
[53]:
def print_coef(model, columns):
"""Plot logistic regression model coefficients"""
coef = pd.DataFrame(
np.transpose(model.coef_), index=columns, columns=["Coefficients"]
)
coef = coef.sort_values(by=["Coefficients"])
plt.figure(figsize=(15, 6))
plt.scatter(x=range(len(coef)), y=coef["Coefficients"])
plt.xticks(range(len(coef)), coef.index, rotation="vertical")
plt.ylabel("LR coefficients")
plt.show()
[54]:
print_coef(model, X_train[selected_features_sfs].columns)
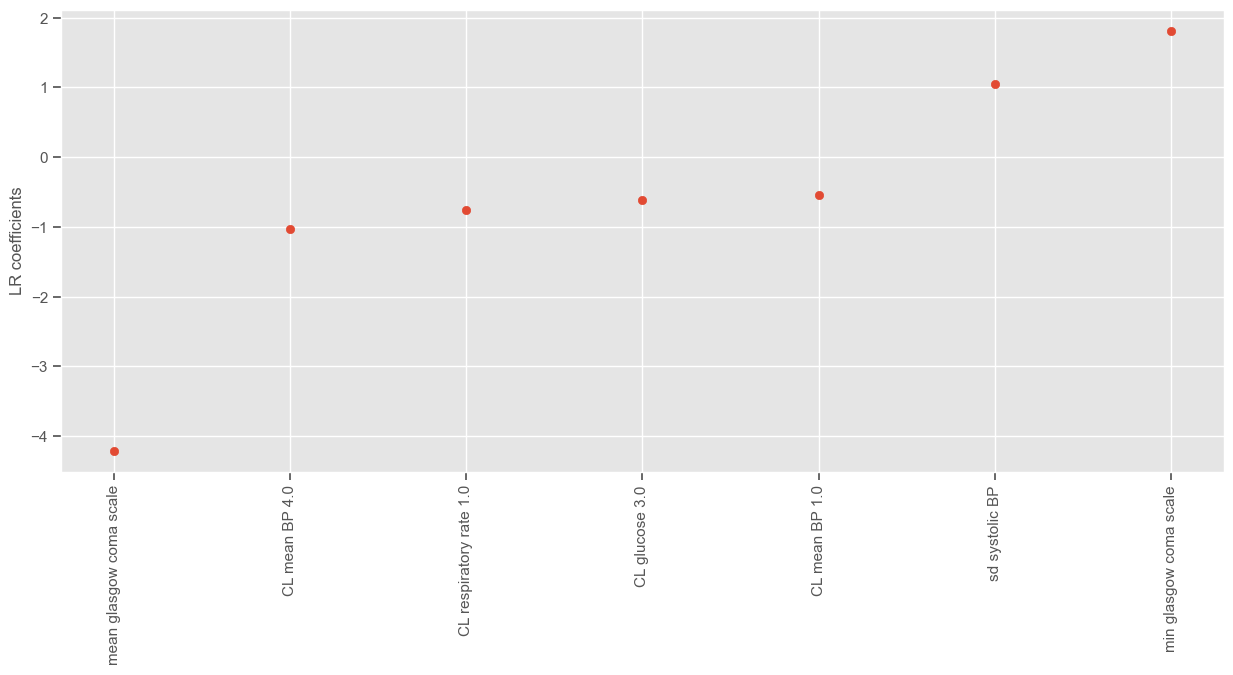
The results seem to cohere with expected clinical practice. There are enough variables in the model which correlate with mortality as we would expect them to. This increases our faith in the remainder of those variables whose association with mortality in clinical practice is not inherently obvious. The results evoke interesting relationships between other variables which are less well known to affect mortality, such as, for instance, glucose.
The same process can be repeated for RFE:
[55]:
model = LogisticRegression(random_state=1)
model.fit(X_train[selected_features_rfe], y_train.values.ravel())
results_train, results_test, y_pred_prob_train, y_pred_prob_test = model_evaluation(
model,
X_train[selected_features_rfe],
y_train,
X_test[selected_features_rfe],
y_test,
print_=1,
)
print_coef(model, X_train[selected_features_rfe].columns)
all_results_train = all_results_train.append(
results_train.rename(index={results_train.index[-1]: "LR RFE"})
)
all_results_test = all_results_test.append(
results_test.rename(index={results_test.index[-1]: "LR RFE"})
)
TRAINING SET
Threshold: 0.3
TP: 76
TN: 135
FP: 14
FN: 8
Accuracy: 0.91
Sensitivity: 0.9
Specificity: 0.91
AUC: 0.97
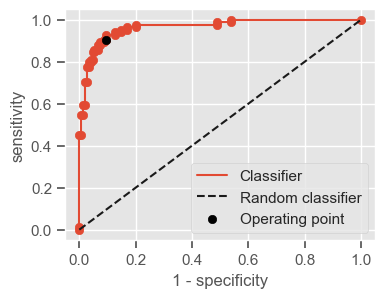
TEST SET
Threshold: 0.3
TP: 21
TN: 379
FP: 55
FN: 3
Accuracy: 0.87
Sensitivity: 0.88
Specificity: 0.87
AUC: 0.95
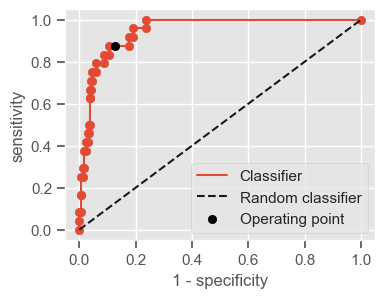
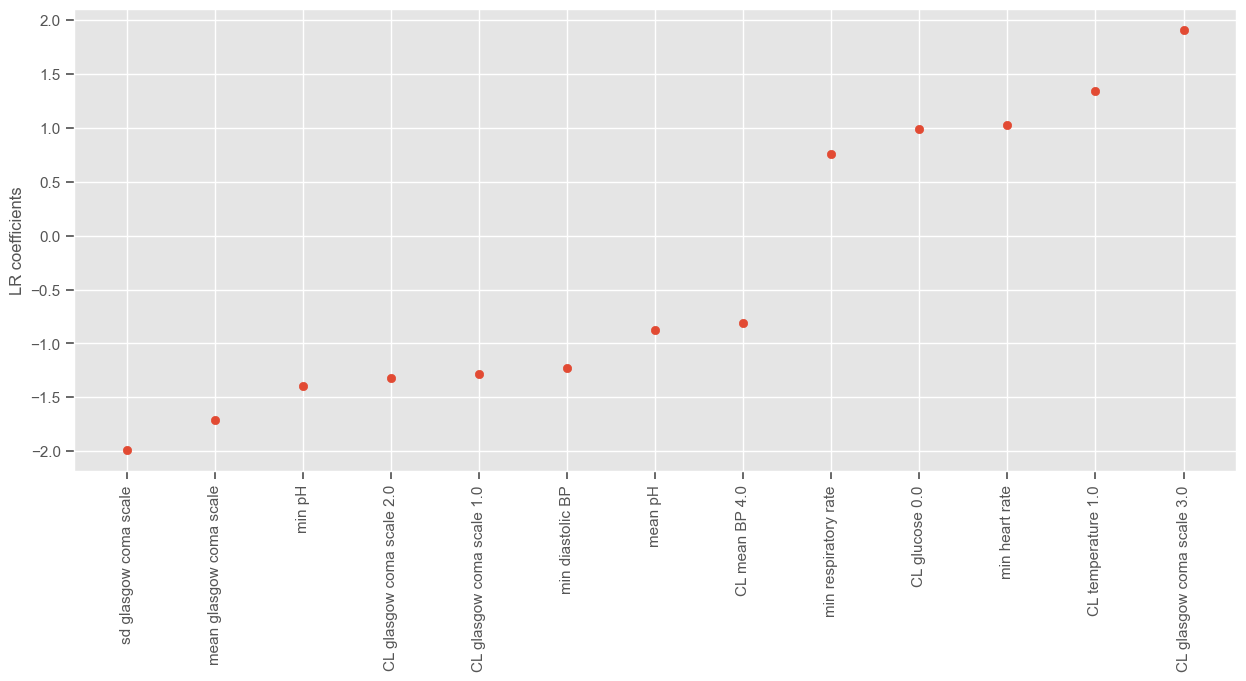
k-Nearest neighbors (kNN)#
Another simple algorithm investigated in this work is k-nearest neighbors (kNN). It is known as a “lazy” algorithm, since it does not do anything during the learning phase: the model is essentially the entire training dataset. When a prediction is required for an unseen observation, kNN will search through the entire training set for the (k) most similar observations. The prediction is given by the majority voting of those (k) nearest neighbors. The similarity measure is dependent on the type of data. For real-valued data, the Euclidean distance can be used. For other types of data, such as categorical or binary data, the Hamming distance is recommended. In this work we focus only on the Euclidean distance.
A very common alternative to the straightforward kNN is weighted kNN, where each point has a weight proportional to its distance. For example, with inverse distance weighting, each point has a weight equal to the inverse of its distance to the point to be classified. This means that neighboring points have a higher vote than farther points. As an example, we will use the ‘KNeighborsClassifier’ function from ‘sklearn’ with 3 neighbors, the parameter ‘weights’ set to ‘distance’, in order to have weighted votes and the features selected through SFS.
Warning: In ‘sklearn’, if there is a tie in majority voting, for instance if you provide \(k = 2\) and the two neighbors have identical distances but different class labels, the results will depend on the ordering of the training data. Therefore, it is recommended to use an odd number of k.
[56]:
from sklearn.neighbors import KNeighborsClassifier
# instantiate learning model
knn = KNeighborsClassifier(n_neighbors=3, weights="distance")
# fitting the model
knn.fit(X_train[selected_features_sfs], y_train.values.ravel())
# predict the response
y_pred = knn.predict(X_test[selected_features_sfs])
# evaluate the performance
threshold, AUC_test, sens_test, spec_test = performance(
y_test, pd.DataFrame(y_pred), print_=1
)
# save the results
all_results_test.loc["KNN SFS"] = [
threshold,
AUC_test,
sens_test,
spec_test,
len(selected_features_sfs),
]
all_results_train.loc["KNN SFS"] = np.nan
Threshold: 1.0
TP: 16
TN: 385
FP: 49
FN: 8
Accuracy: 0.88
Sensitivity: 0.67
Specificity: 0.89
AUC: 0.78
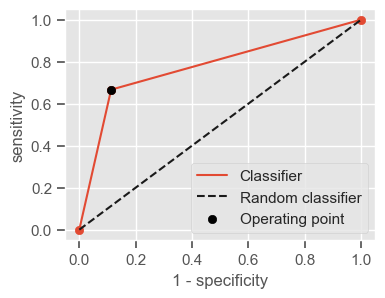
Running the same algorithm with the features selected through RFE yields very similar results. You can check for yourself by substituting the input vector in the previous script.
Decision tree#
Most ICU severity scores are constructed using logistic regression, which imposes stringent constraints on the relationship between explanatory variables and outcome. In particular, logistic regression relies on the assumption of a linear and additive relationship between the outcome and its predictors. Given the complexity of the processes underlying death in ICU patients, this assumption might be unrealistic.
We hope to improve the prediction obtained by LR by using a nonparametric algorithm such as a decision tree. A decision tree is a model that uses a tree–like graph of rules that give probabilities of outcome. It can be used for classification and regression, it automatically performs feature selection, it is easy to understand, interpret (as long as the tree has a small depth and low number of features) and requires little data preparation. Since this type of algorithm does not make strong assumptions about the form of the mapping function, they are good candidates when you have a lot of data and no prior knowledge, and when you do not want to worry too much about choosing the right features.
However, decision trees learners are associated with several disadvantages. They are prone to overfitting, as they tend to create over-complex trees that do not generalize well, and they can be unstable because small variations in the data might result in a completely different trees being generated. Methods like bagging and boosting, for example random forests, are typically used to solve these issues.
The reader is referred to \cite{https://machinelearningmastery.com/classification-and-regression-trees-for-machine-learning/} for more information on decision trees.
CART algorithm#
This work will focus on the CART algorithm, which is one of the most popular algorithms for learning a decision tree. The selection of variables and the specific split is chosen using a greedy algorithm to minimize a cost function. Tree construction ends using a predefined stopping criterion, such as a minimum number of training instances assigned to each leaf node of the tree.
Greedy Splitting#
The greedy search consists of recursive binary splitting, a process of dividing up the input space. All input variables and all possible split points are evaluated and chosen in a greedy manner (the very best split point is chosen each time). All values are lined up and different split points are tried and tested using a cost function. The split with the lowest cost is selected.
For classification, the Gini index (G) function (also known as Gini impurity) is used. It provides an indication of how “pure” the leaf nodes are, or in other words, an idea of how good a split is by how mixed the classes are in the two groups created by the split:
perfect class purity: a node that has all classes of the same (\(G=0\))
worst class purity: a node that has a 50-50 split of classes (\(G=0.5\))
The \(G\) for each node is weighted by the total number of instances in the parent node. For a chosen split point in a binary classification problem, \(G\) is calculated as:
\(G = ((1 -g1_1^2 + g1_2^2) \times \frac{ng1}{n})+ ((1 - g2_1^2 + g2_2^2) \times \frac{ng2}{n})\), where: * \(g1_1\): proportion of instances in group 1 for class 1 * \(g1_2\): proportion of instances in group 1 for class 2 * \(g2_1\): proportion of instances in group 2 for class 1 * \(g2_2\): proportion of instances in group 2 for class 2 * \(ng1\): total number of instances in group 1 * \(ng2\): total number of instances in group 2 * \(n\): total number of instances we are trying to group from the parent node
Stopping Criterion#
The most common stopping procedure is to use a minimum count of the number of training observations assigned to each leaf node. If the count is less than some minimum then the split is not accepted and the node is taken as a final leaf node. The minimum count of training observations is tuned to the dataset. It defines how specific to the training data the tree will be. Too specific (e.g. a count of 1) and the tree will overfit the training data and likely have poor performance on the test set.
The CART algorithm can be implemented in sklearn using the ‘DecisionTreeClassifier’ function from sklearn.ensemble. Next follows a list of important parameters to have in consideration when training the model:
criterion: function to measure the quality of a split. Default=”gini”
splitter: strategy used to choose the split at each node. Supported strategies are “best” to choose the best split and “random” to choose the best random split. Default=”best”
max_features: maximum number of features in each tree. Default is sqrt(n_features)
max_depth: maximum depth of the tree. If None, nodes are expanded until all leaves are pure or until all leaves contain less than min_samples_split samples.
min_samples_split: minimum number of samples required to split an internal node. Default=2
min_samples_leaf: minimum number of samples required to be at a leaf node. Default=1
max_leaf_nodes: grow a tree with max_leaf_nodes in best-first fashion. Best nodes are defined as relative reduction in impurity. If None then unlimited number of leaf nodes. default=None
random_state: if int, seed used by the random number generator. Default=None
In the next example, a small decision tree (maximum depth = 5) is created. Since the algorithm has embedded feature selection, we can use all the extracted features as input without having to worry about dimensionality issues.
[57]:
# from sklearn import tree
from sklearn.tree import DecisionTreeClassifier
clf_gini = DecisionTreeClassifier(
criterion="gini",
max_depth=5,
min_samples_leaf=20,
min_samples_split=20,
random_state=2,
splitter="best",
)
clf_gini.fit(X_train, y_train)
results_train, results_test, y_pred_prob_train, y_pred_prob_test = model_evaluation(
clf_gini, X_train, y_train, X_test, y_test, print_=1
)
TRAINING SET
Threshold: 0.5
TP: 73
TN: 131
FP: 18
FN: 11
Accuracy: 0.88
Sensitivity: 0.87
Specificity: 0.88
AUC: 0.95
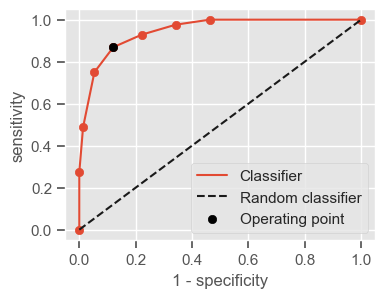
TEST SET
Threshold: 0.5
TP: 18
TN: 344
FP: 90
FN: 6
Accuracy: 0.79
Sensitivity: 0.75
Specificity: 0.79
AUC: 0.86

There are two major sources of error in machine learning: bias and variance:
Bias: how the algorithm performs on the training set.
Variance: how much worse the algorithm does on the test set than the training set.
Understanding them will help you decide which tactics to improve performance are a good use of time. High bias can be viewed as an underfitting problem, and high variance as an overfitting problem. Comparing the training and test results, it seems that the DT is overfitting the training data (high variance). You can investigate how bias and variance are affected by different choices of parameters.
Tree visualization#
In order to visualize the tree, some extra packages need to be installed (‘pydot’ and ‘graphviz’). Use the following example to visualize the tree created in the previous step:
[58]:
# from sklearn.externals.six import StringIO
from six import StringIO
from IPython.display import Image
from sklearn.tree import export_graphviz
import pydotplus
dot_data = StringIO()
export_graphviz(
clf_gini,
out_file=dot_data,
filled=True,
rounded=True,
special_characters=True,
class_names=["survival", "non-survival"],
feature_names=X_train.columns,
)
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
Image(graph.create_png())
[58]:
With the binary tree representation shown above, making predictions is relatively straightforward.
Feature importance#
As you can see in the previous figure, not all features are selected. The ‘feature_importances_’ attribute gives the relative importance of each feature in the model. The importance of a feature is computed as the (normalized) total reduction of the criterion brought by that feature. It is also known as the Gini importance. Features with relative importance greater than 0 correspond to features that were selected by the model. The next example shows how to plot the features in descending order of relative importance.
[59]:
def plot_feat_importance(columns, feature_importances_, *topx):
list_feat = list(zip(columns, feature_importances_))
pd_list_feat = pd.DataFrame(list_feat)
pd_list_feat.columns = ("Feature", "Importance")
pd_list_feat = pd_list_feat.sort_values(by="Importance")
pd_list_feat = pd_list_feat[pd_list_feat["Importance"] > 0]
if topx:
pd_list_top = pd_list_feat.iloc[topx[0] :]
else:
pd_list_top = pd_list_feat
plt.figure(figsize=(10, 10))
plt.scatter(y=range(len(pd_list_top)), x=pd_list_top["Importance"])
plt.yticks(range(len(pd_list_top)), pd_list_top["Feature"])
plt.title(
"Relative feature importance of features in decision tree classifier",
ha="right",
)
plt.xlabel("Relative feature importance")
plt.show()
return pd_list_top
pd_list_top = plot_feat_importance(X_train.columns, clf_gini.feature_importances_)
Again, we will store the results, but in this case we need to update the actual number of features used:
[60]:
all_results_train = all_results_train.append(
results_train.rename(index={results_train.index[-1]: "DT"})
)
all_results_test = all_results_test.append(
results_test.rename(index={results_test.index[-1]: "DT"})
)
all_results_train.loc["DT", "# features"] = len(pd_list_top)
all_results_test.loc["DT", "# features"] = len(pd_list_top)
Random forest#
Random forest comprises split-variable selection, sub-sampling and bootstrap aggregating (bagging).
“The essential idea in bagging is to average many noisy but approximately unbiased models, and hence reduce the variance. Trees are ideal candidates for bagging, since they can capture complex interaction structures in the data, and if grown sufficiently deep, have relatively low bias. Since trees are notoriously noisy, they benefit greatly from the averaging”. Friedman et al. - 2008 - The Elements of Statistical Learning.
Next follows a description of the Random Forest algorithm for classification during the learning and test phases:
Training#
\(B:\) Number of trees
For \(b=1\) to \(B\)
1.1. Draw a bootstrap sample of size \(N_b\) from the training data (bootstrap = random sampling with replacement).
1.2. Grow a random tree \(T_b\) to the bootstrapped data, by recursively repeating the following steps for each terminal node of the tree, until the minimum node size \(n_{min}\) is reached. See CART algorithm.
Select m variables at random from the \(p\) variables
Pick the best variable/split-point among \(m\)
Split the node into two daughter nodes
Output the ensemble of trees
Testing#
Let \(C_b(x_i)\) be the predicted class probability of the \(b\)th tree in the ensemble for observation \(x_i\). Then, the predicted class probability of the random forest for observation \(x_i\) is:
\(C_{rf}^B(x_i)= \frac{1}{B}\sum_{b=1}^{B}C_b(x_i)\)
The predicted class probabilities of an input sample are computed as the mean predicted class probabilities of the trees in the forest. The class probability of a single tree is the fraction of samples of the same class in a leaf.
The algorithm can be implemented in ‘sklearn’ using the ‘RandomForestClassifier’. Similarly to the decision tree, important parameters to define are:
n_estimators: number of trees in the forest.
criterion: function to measure the quality of a split. Default=”gini”
max_features: maximum number of features in each tree. Default is sqrt(n_features)
max_depth: maximum depth of the tree. If None, then nodes are expanded until all leaves are pure or until all leaves contain less than min_samples_split samples.
min_samples_split: minimum number of samples required to split an internal node. Default=2
min_samples_leaf: minimum number of samples required to be at a leaf node (external node). Default=1
random_state: if int, seed used by the random number generator. Default=None
bootstrap: Whether bootstrap samples are used when building trees. The sub-sample size is always the same as the original input sample size but the samples are drawn with replacement if bootstrap=True. Default=True
The next example shows how to build a RF classifier with 100 trees and a maximum depth of 10:
[61]:
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier(
n_estimators=100, bootstrap=True, criterion="gini", max_depth=10, random_state=2
)
rf.fit(X_train, y_train.values.ravel())
results_train, results_test, y_pred_prob_train, y_pred_prob_test = model_evaluation(
rf, X_train, y_train, X_test, y_test, print_=1
)
all_results_train = all_results_train.append(
results_train.rename(index={results_train.index[-1]: "RF"})
)
all_results_test = all_results_test.append(
results_test.rename(index={results_test.index[-1]: "RF"})
)
TRAINING SET
Threshold: 0.61
TP: 84
TN: 149
FP: 0
FN: 0
Accuracy: 1.0
Sensitivity: 1.0
Specificity: 1.0
AUC: 1.0
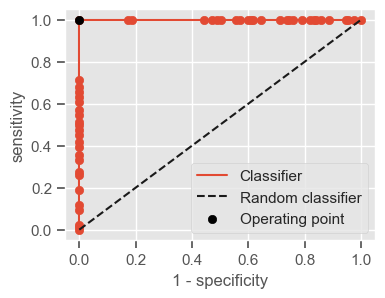
TEST SET
Threshold: 0.61
TP: 18
TN: 420
FP: 14
FN: 6
Accuracy: 0.96
Sensitivity: 0.75
Specificity: 0.97
AUC: 0.97
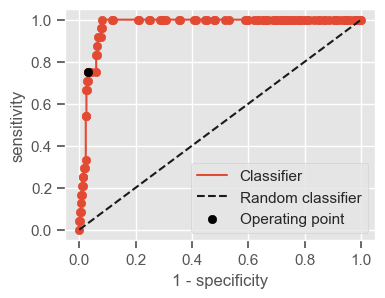
As you can see, in the previous RF configuration the training error is very low. This should make you suspect of/expect high variance. In fact, the performance in the test set is significantly lower. In order to reduce overfitting, we can reduce the depth of the trees and increase the ‘min_samples_split’.
[62]:
from sklearn.ensemble import RandomForestClassifier
print_ = 1
rf = RandomForestClassifier(
n_estimators=100,
bootstrap=True,
criterion="gini",
max_depth=7,
min_samples_split=30,
random_state=2,
)
rf.fit(X_train, y_train.values.ravel())
results_train, results_test, y_pred_prob_train, y_pred_prob_test = model_evaluation(
rf, X_train, y_train, X_test, y_test, print_
)
all_results_train = all_results_train.append(
results_train.rename(index={results_train.index[-1]: "RF small"})
)
all_results_test = all_results_test.append(
results_test.rename(index={results_test.index[-1]: "RF small"})
)
TRAINING SET
Threshold: 0.46
TP: 79
TN: 138
FP: 11
FN: 5
Accuracy: 0.93
Sensitivity: 0.94
Specificity: 0.93
AUC: 0.99
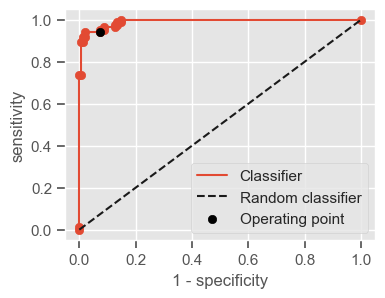
TEST SET
Threshold: 0.46
TP: 24
TN: 392
FP: 42
FN: 0
Accuracy: 0.91
Sensitivity: 1.0
Specificity: 0.9
AUC: 0.98
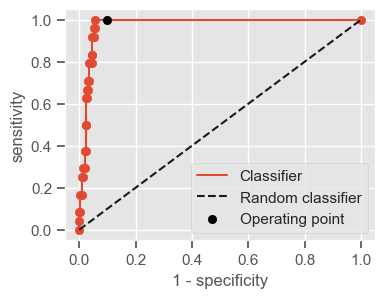
We were able to decrease the variance, but we still have moderate performance in the test set. Ideally, the performance should be evaluated for various combinations of parameters, and the combination giving the best performance should be selected. The performance of the selected set could then be evaluated using a test set not used before.
Feature importance#
At each split in each tree, the improvement in the split-criterion (\(G\)) is the importance measure attributed to the splitting feature, and is accumulated over all the trees in the forest separately for each feature. The same function created for DT can be used for RF:
[63]:
pd_list_top = plot_feat_importance(X_train.columns, rf.feature_importances_, 40)
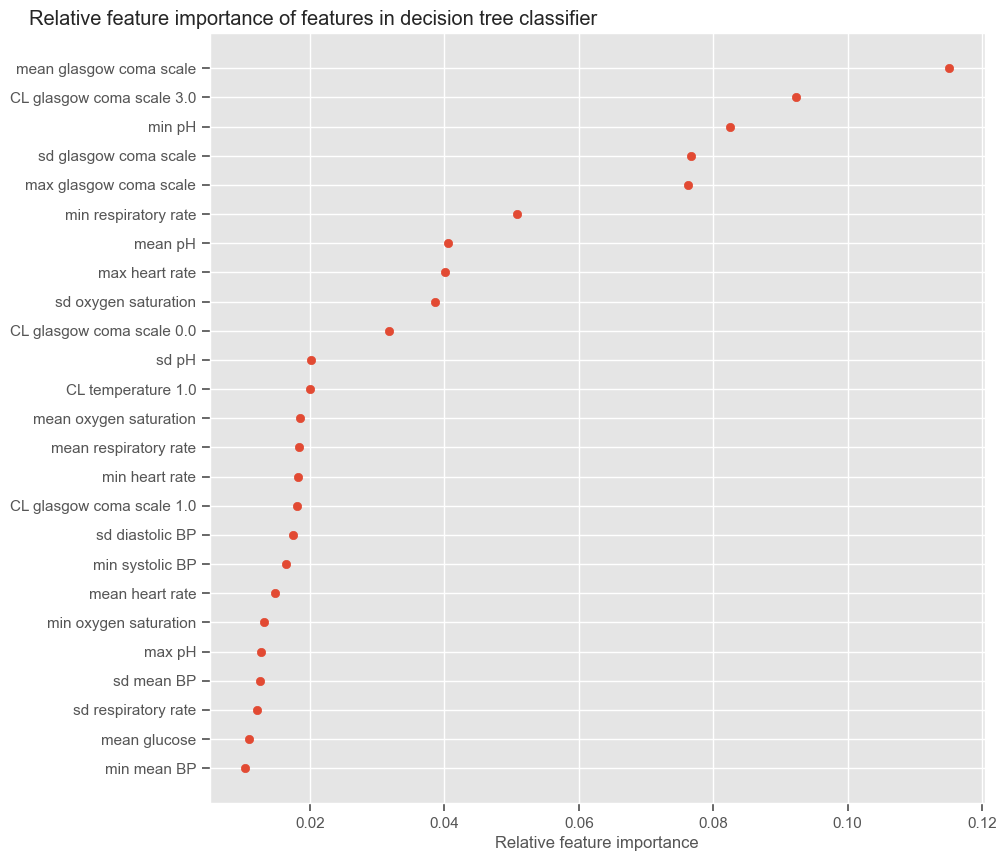
Update the actual number of features used in the RF:
[64]:
all_results_train.loc["RF small", "# features"] = len(pd_list_top)
all_results_test.loc["RF small", "# features"] = len(pd_list_top)
The features to which RF assigns higher feature importance are consistent with previous findings. Several features extracted from GCS appear at the top.
Comparison of classifiers#
The next example summarizes the performance of several classifiers and their ability to generalize. For better assessing the classifiers ability to generalize, the difference between training and test performance is plotted.
[65]:
print("Performance in training set")
display.display(np.round(all_results_train, decimals=2))
print()
print("Performance in test set")
display.display(np.round(all_results_test, decimals=2))
print()
diff = all_results_train - all_results_test
diff[["AUC", "Sensitivity", "Specificity"]].plot(kind="bar", figsize=(10, 3))
plt.ylabel("Difference in performance")
plt.xticks(rotation=None)
plt.title("Difference in performance (training - test)")
plt.show()
Performance in training set
| Threshold | AUC | Sensitivity | Specificity | # features | |
|---|---|---|---|---|---|
| LR SFS | 0.36 | 0.91 | 0.87 | 0.87 | 7.0 |
| LR RFE | 0.30 | 0.97 | 0.90 | 0.91 | 13.0 |
| KNN SFS | NaN | NaN | NaN | NaN | NaN |
| DT | 0.50 | 0.95 | 0.87 | 0.88 | 7.0 |
| RF | 0.61 | 1.00 | 1.00 | 1.00 | 85.0 |
| RF small | 0.46 | 0.99 | 0.94 | 0.93 | 25.0 |
Performance in test set
| Threshold | AUC | Sensitivity | Specificity | # features | |
|---|---|---|---|---|---|
| LR SFS | 0.36 | 0.88 | 0.83 | 0.87 | 7.0 |
| LR RFE | 0.30 | 0.95 | 0.88 | 0.87 | 13.0 |
| KNN SFS | 1.00 | 0.78 | 0.67 | 0.89 | 7.0 |
| DT | 0.50 | 0.86 | 0.75 | 0.79 | 7.0 |
| RF | 0.61 | 0.97 | 0.75 | 0.97 | 85.0 |
| RF small | 0.46 | 0.98 | 1.00 | 0.90 | 25.0 |
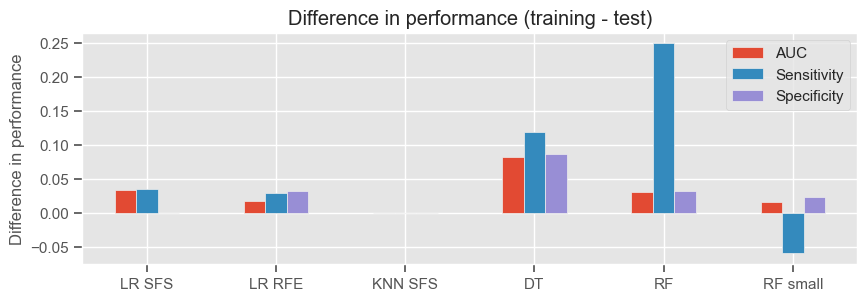
Limitations#
In the next section, critical aspects of the study conducted are discussed.
Selecting one model#
What is the best model? At this point it is probable that the reader is posing this question. The answer to what is the best model, or what model should be selected, is not straightforward. At this point, it really is about selecting a good path to continue exploring. A single decision tree is clearly not the way to go in terms of performance, but it can be useful if interpretability is a must. LR is also interpretable when the feature set contains a resonable number of features. So if interpretability is important, LF with RFE or SFS should be considered. RF performs well in the test set but the increase in performance relatively to simpler models is very small. The choice depends on reaching a good trade-off between what’s more important; e.g., if sensitivity is very important, and not so much interpretability, them the first RF should be chosen.
Training test and validation#
Before making any conclusions about the performance, it is advisable to change the data partitions used for training, testing and validating. A single data partitioning has been used in order to facilitate the presentation of ideas, but ideally the evaluation should not be limited to a single random data division. Cross validation can be used to investigate the variablity in performance when different data partitions are used. Following this approach, all data is used for training and testing the models and the results are averaged over the rounds.
Bias/variance#
Decision tree based models have high variance, i.e., the trees are probably overfitting the training data and this hampers their ability to generalize. Again, cross-validation should be performed - we would probably get very different DTs for different training partitions (which is why RF is better!). As mentioned before, the bias/variance problem could be addressed by training/validating models for a range of distinct combinations of parameters and selecting a set that minimizes overfit to the training data (low bias) and that at the same time performs well in the validation set (low variance).
Exercises#
Daily prediction#
It is useful to evaluate the performance of the classifier using data from the first day. It will give us a more realistic sense of how the classifier would behave in a real setting if we wanted a decision at the end of the first day.
We have performed dimensionality reduction by extracting relevant information from the time series and we have done this for the complete series (48h). Your job is to do this separately for each 24h and see how the performance changes.
Clustering patterns#
Clustering has been employed for patient stratification. Data were normalized for each patient individually so that the groups would reflect physiological time trends. How do the patterns change if:
the random seed used to generate the training and test sets changes;
the random seed used to initiate the cluster centers changes;
data is not normalized;
data is normalized for the entire training set at once?
Class imbalance#
Undersampling has been used in order to mitigate bias toward a predominant class. Class balancing can also be performed by sampling an equal number of observations from each class. In ‘sklearn’, you can use the parameter ‘class_weight’ in order to control for imbalanced training data when learning logistic regression, decision trees or random forest:
class_weight = {class_label: weight}: weights associated with classes. If not given, all classes are supposed to have weight one.
class_weight = ‘balanced’: uses the values of y to automatically adjust weights inversely proportional to class frequencies in the input data. It basically increases the weight of making an error with the under-represented class.
Investigate how class_weight=’balanced’ impacts the performance of the models.
Bias/Variance#
Investigate how bias and variance are affected by different choices of parameters.
Recommended literature#
Machine Learning Yearning (2018) by Andre Ng (draft version currently available)
The elements of statistical learning (2001) by Friedman J, Hastie T, Tibshirani R.
Secondary Analysis of Electronic Health Records (2016) by MIT Critical Data
Python Data Science Handbook (2016) by Jake VanderPlas
Hands-On Machine Learning with Scikit-Learn and TensorFlow (2017) by Aurélien Géron